1、為什么要使用多線程
選擇多線程的原因,就是因為快。舉個例子:
如果要把1000塊磚搬到樓頂 ,假設到樓頂有幾個電梯,你覺得用一個電梯搬運快,還是同時用幾個電梯同時搬運快呢?這個電梯就可以理解為線程。
所以,我們使用多線程就是因為: 在正確的場景下,設置恰當數目的線程,可以用來程提高序的運行速率。更專業點講,就是充分地利用CPU和I/O的利用率,提升程序運行速率。
當然,有利就有弊,多線程場景下,我們要保證線程安全,就需要考慮加鎖。加鎖如果不恰當,就很很耗性能。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/ruoyi-vue-pro
視頻教程:https://doc.iocoder.cn/video/
2. 創建線程有幾種方式?
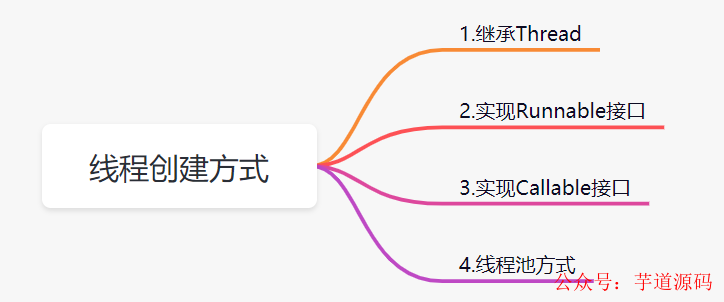
Java中創建線程主要有以下這幾種方式:
定義Thread類的子類,并重寫該類的run方法
定義Runnable接口的實現類,并重寫該接口的run()方法
定義Callable接口的實現類,并重寫該接口的call()方法,一般配合Future使用
線程池的方式
2.1 定義Thread類的子類,并重寫該類的run方法
?
?
public?class?ThreadTest?{
????public?static?void?main(String[]?args)?{
????????Thread?thread?=?new?MyThread();
????????thread.start();
????}
}
class?MyThread?extends?Thread?{
????@Override
????public?void?run()?{
????????System.out.println("關注公?眾號:芋道源碼");
????}
}
?
?
2.2 定義Runnable接口的實現類,并重寫該接口的run()方法
?
?
public?class?ThreadTest?{
????public?static?void?main(String[]?args)?{
????????MyRunnable?myRunnable?=?new?MyRunnable();
????????Thread?thread?=?new?Thread(myRunnable);
????????thread.start();
????}
}
class?MyRunnable?implements?Runnable?{
????@Override
????public?void?run()?{
????????System.out.println("關注公眾號:芋道源碼");
????}
}
//運行結果:
關注公眾號:芋道源碼
?
?
2.3 定義Callable接口的實現類,并重寫該接口的call()方法
如果想要執行的線程有返回,可以使用Callable。
?
?
public?class?ThreadTest?{
????public?static?void?main(String[]?args)?throws?ExecutionException,?InterruptedException?{
????????MyThreadCallable?mc?=?new?MyThreadCallable();
????????FutureTask?ft?=?new?FutureTask<>(mc);
????????Thread?thread?=?new?Thread(ft);
????????thread.start();
????????System.out.println(ft.get());
????}
}
class?MyThreadCallable?implements?Callable?{
????@Override
????public?String?call()throws?Exception?{
????????return?"關注公眾號:芋道源碼";
????}
}
//運行結果:
關注公眾號:芋道源碼
?
?
2.4 線程池的方式
日常開發中,我們一般都是用線程池的方式執行異步任務。
?
?
public?class?ThreadTest?{
????public?static?void?main(String[]?args)?throws?Exception?{
????????ThreadPoolExecutor?executorOne?=?new?ThreadPoolExecutor(5,?5,?1,
????????????????TimeUnit.MINUTES,?new?ArrayBlockingQueue(20),?new?CustomizableThreadFactory("Tianluo-Thread-pool"));
????????executorOne.execute(()?->?{
????????????System.out.println("關注公眾號:芋道源碼");
????????});
????????//關閉線程池
????????executorOne.shutdown();
????}
}
?
?
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/yudao-cloud
視頻教程:https://doc.iocoder.cn/video/
3. start()方法和run()方法的區別
其實start和run的主要區別如下:
start方法可以啟動一個新線程,run方法只是類的一個普通方法而已,如果直接調用run方法,程序中依然只有主線程這一個線程。
start方法實現了多線程,而run方法沒有實現多線程。
start不能被重復調用,而run方法可以。
start方法中的run代碼可以不執行完,就繼續執行下面的代碼,也就是說進行了線程切換 。然而,如果直接調用run方法,就必須等待其代碼全部執行完才能繼續執行下面的代碼。
大家可以結合代碼例子來看看哈~
?
?
public?class?ThreadTest?{
????public?static?void?main(String[]?args){
????????Thread?t=new?Thread(){
????????????public?void?run(){
????????????????pong();
????????????}
????????};
????????t.start();
????????t.run();
????????t.run();
????????System.out.println("好的,馬上去關注:關注公眾號:芋道源碼"+?Thread.currentThread().getName());
????}
????static?void?pong(){
????????System.out.println("關注公眾號:芋道源碼"+?Thread.currentThread().getName());
????}
}
//輸出
關注公眾號:芋道源碼main
關注公眾號:芋道源碼main
好的,馬上去關注:關注公眾號:芋道源碼main
關注公眾號:芋道源碼Thread-0
?
?
4. 線程和進程的區別
進程是運行中的應用程序,線程是進程的內部的一個執行序列
進程是資源分配的最小單位,線程是CPU調度的最小單位。
一個進程可以有多個線程。線程又叫做輕量級進程,多個線程共享進程的資源
進程間切換代價大,線程間切換代價小
進程擁有資源多,線程擁有資源少地址
進程是存在地址空間的,而線程本身無地址空間,線程的地址空間是包含在進程中的
舉個例子:
你打開QQ,開了一個進程;打開了迅雷,也開了一個進程。
在QQ的這個進程里,傳輸文字開一個線程、傳輸語音開了一個線程、彈出對話框又開了一個線程。
所以運行某個軟件,相當于開了一個進程。在這個軟件運行的過程里(在這個進程里),多個工作支撐的完成QQ的運行,那么這“多個工作”分別有一個線程。
所以一個進程管著多個線程。
通俗的講:“進程是爹媽,管著眾多的線程兒子”...
5. 說一下 Runnable 和 Callable有什么區別?
Runnable接口中的run()方法沒有返回值,是void類型,它做的事情只是純粹地去執行run()方法中的代碼而已;
Callable接口中的call()方法是有返回值的,是一個泛型。它一般配合Future、FutureTask一起使用,用來獲取異步執行的結果。
Callable接口call()方法允許拋出異常;而Runnable接口run()方法不能繼續上拋異常;
大家可以看下它倆的API:
?
?
?@FunctionalInterface
public?interface?Callable?{
????/**
?????*?支持泛型V,有返回值,允許拋出異常
?????*/
????V?call()?throws?Exception;
}
@FunctionalInterface
public?interface?Runnable?{
????/**
?????*??沒有返回值,不能繼續上拋異常
?????*/
????public?abstract?void?run();
}
?
?
為了方便大家理解,寫了一個demo,小伙伴們可以看看哈:
?
?
/*
?*??@Author?關注公眾號:芋道源碼
?*??@date?2022-07-11
?*/
public?class?CallableRunnableTest?{
????public?static?void?main(String[]?args)?{
????????ExecutorService?executorService?=?Executors.newFixedThreadPool(5);
????????Callable?callable?=new?Callable()?{
????????????@Override
????????????public?String?call()?throws?Exception?{
????????????????return?"你好,callable,關注公眾號:芋道源碼";
????????????}
????????};
????????//支持泛型
????????Future?futureCallable?=?executorService.submit(callable);
????????try?{
????????????System.out.println("獲取callable的返回結果:"+futureCallable.get());
????????}?catch?(InterruptedException?e)?{
????????????e.printStackTrace();
????????}?catch?(ExecutionException?e)?{
????????????e.printStackTrace();
????????}
????????Runnable?runnable?=?new?Runnable()?{
????????????@Override
????????????public?void?run()?{
????????????????System.out.println("你好呀,runnable,關注公眾號:芋道源碼");
????????????}
????????};
????????Future?futureRunnable?=?executorService.submit(runnable);
????????try?{
????????????System.out.println("獲取runnable的返回結果:"+futureRunnable.get());
????????}?catch?(InterruptedException?e)?{
????????????e.printStackTrace();
????????}?catch?(ExecutionException?e)?{
????????????e.printStackTrace();
????????}
????????executorService.shutdown();
????}
}
//運行結果
獲取callable的返回結果:你好,callable,關注公眾號:芋道源碼
你好呀,runnable,關注公眾號:芋道源碼
獲取runnable的返回結果:null
?
?
6. 聊聊volatile作用,原理
volatile關鍵字是Java虛擬機提供的的最輕量級的同步機制。它作為一個修飾符,用來修飾變量。它保證變量對所有線程可見性,禁止指令重排,但是不保證原子性 。
我們先來一起回憶下java內存模型(jmm):
Java虛擬機規范試圖定義一種Java內存模型,來屏蔽掉各種硬件和操作系統的內存訪問差異,以實現讓Java程序在各種平臺上都能達到一致的內存訪問效果。
Java內存模型規定所有的變量都是存在主內存當中,每個線程都有自己的工作內存。這里的變量包括實例變量和靜態變量,但是不包括局部變量,因為局部變量是線程私有的。
線程的工作內存保存了被該線程使用的變量的主內存副本,線程對變量的所有操作都必須在工作內存中進行,而不能直接操作主內存。并且每個線程不能訪問其他線程的工作內存。
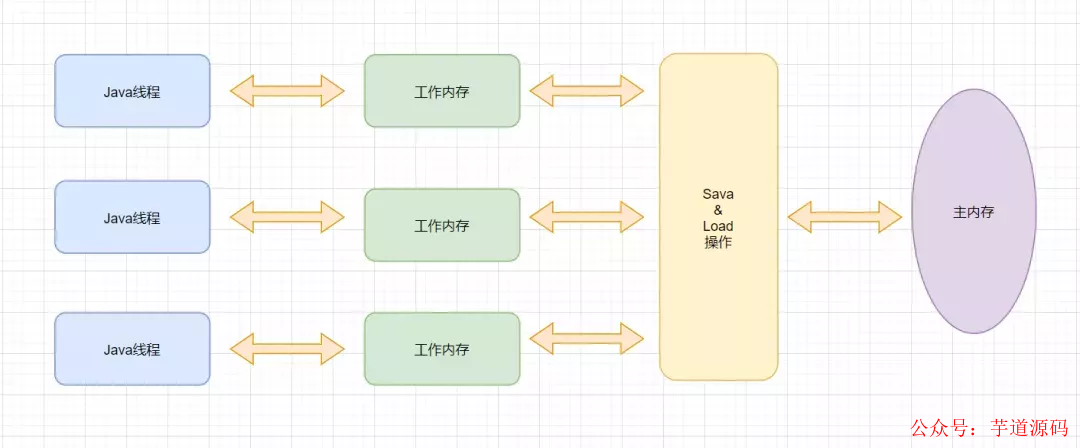
volatile變量,保證新值能立即同步回主內存,以及每次使用前立即從主內存刷新,所以我們說volatile保證了多線程操作變量的可見性。
volatile保證可見性和禁止指令重排,都跟內存屏障有關。我們來看一段volatile使用的demo代碼:
?
?
/**
?*?關注公眾號:芋道源碼
?**/
public?class?Singleton?{??
???private?volatile?static?Singleton?instance;??
???private?Singleton?(){}??
???public?static?Singleton?getInstance()?{??
???if?(instance?==?null)?{??
???????synchronized?(Singleton.class)?{??
???????if?(instance?==?null)?{??
???????????instance?=?new?Singleton();??
???????}??
???????}??
???}??
???return?instance;??
???}??
}??
?
?
編譯后,對比有volatile關鍵字和沒有volatile關鍵字時所生成的匯編代碼,發現有volatile關鍵字修飾時,會多出一個lock addl $0x0,(%esp),即多出一個lock前綴指令,lock指令相當于一個內存屏障
lock指令相當于一個內存屏障,它保證以下這幾點:
重排序時不能把后面的指令重排序到內存屏障之前的位置
將本處理器的緩存寫入內存
如果是寫入動作,會導致其他處理器中對應的緩存無效。
第2點和第3點就是保證volatile保證可見性的體現嘛,第1點就是禁止指令重排的體現 。
內存屏障四大分類:(Load 代表讀取指令,Store代表寫入指令)
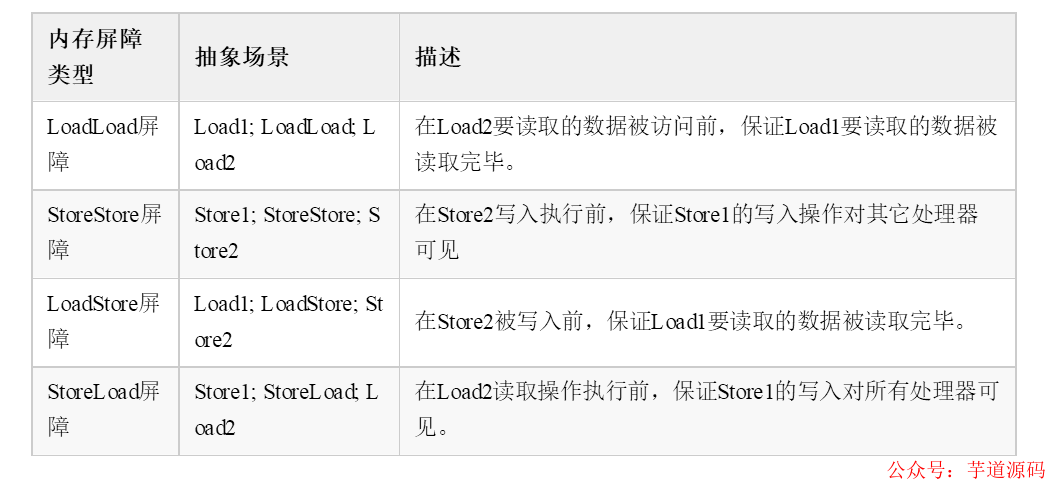
在每個volatile寫操作的前面插入一個StoreStore屏障。
在每個volatile寫操作的后面插入一個StoreLoad屏障。
在每個volatile讀操作的后面插入一個LoadLoad屏障。
在每個volatile讀操作的后面插入一個LoadStore屏障。
有些小伙伴,可能對這個還是有點疑惑,內存屏障這玩意太抽象了。我們照著代碼看下吧:

內存屏障保證前面的指令先執行,所以這就保證了禁止了指令重排啦,同時內存屏障保證緩存寫入內存和其他處理器緩存失效,這也就保證了可見性,哈哈~有關于volatile的底層實現,我們就討論到這哈~
7. 說說并發與并行的區別?
并發和并行最開始都是操作系統 中的概念,表示的是CPU執行多個任務的方式。
順序:上一個開始執行的任務完成后,當前任務才能開始執行
并發:無論上一個開始執行的任務是否完成,當前任務都可以開始執行
(即 A B 順序執行的話,A 一定會比 B 先完成,而并發執行則不一定。)
串行:有一個任務執行單元,從物理上就只能一個任務、一個任務地執行
并行:有多個任務執行單元,從物理上就可以多個任務一起執行
(即在任意時間點上,串行執行時必然只有一個任務在執行,而并行則不一定。)
知乎有個很有意思的回答 ,大家可以看下:
你吃飯吃到一半,電話來了,你一直到吃完了以后才去接,這就說明你不支持并發也不支持并行。
你吃飯吃到一半,電話來了,你停了下來接了電話,接完后繼續吃飯,這說明你支持并發。
你吃飯吃到一半,電話來了,你一邊打電話一邊吃飯,這說明你支持并行。
并發的關鍵是你有處理多個任務的能力,不一定要同時。并行的關鍵是你有同時處理多個任務的能力。所以我認為它們最關鍵的點就是:是否是同時 。
來源:知乎
8.synchronized 的實現原理以及鎖優化?
synchronized是Java中的關鍵字,是一種同步鎖。synchronized關鍵字可以作用于方法或者代碼塊。
一般面試時。可以這么回答:

8.1 monitorenter、monitorexit、ACC_SYNCHRONIZED
如果synchronized 作用于代碼塊 ,反編譯可以看到兩個指令:monitorenter、monitorexit,JVM使用monitorenter和monitorexit兩個指令實現同步;如果作用synchronized作用于方法 ,反編譯可以看到ACCSYNCHRONIZED標記,JVM通過在方法訪問標識符(flags)中加入ACCSYNCHRONIZED來實現同步功能。
同步代碼塊是通過monitorenter和monitorexit來實現,當線程執行到monitorenter的時候要先獲得monitor鎖,才能執行后面的方法。當線程執行到monitorexit的時候則要釋放鎖。
同步方法是通過中設置ACCSYNCHRONIZED標志來實現,當線程執行有ACCSYNCHRONI標志的方法,需要獲得monitor鎖。每個對象都與一個monitor相關聯,線程可以占有或者釋放monitor。
8.2 monitor監視器
monitor是什么呢?操作系統的管程(monitors)是概念原理,ObjectMonitor是它的原理實現。
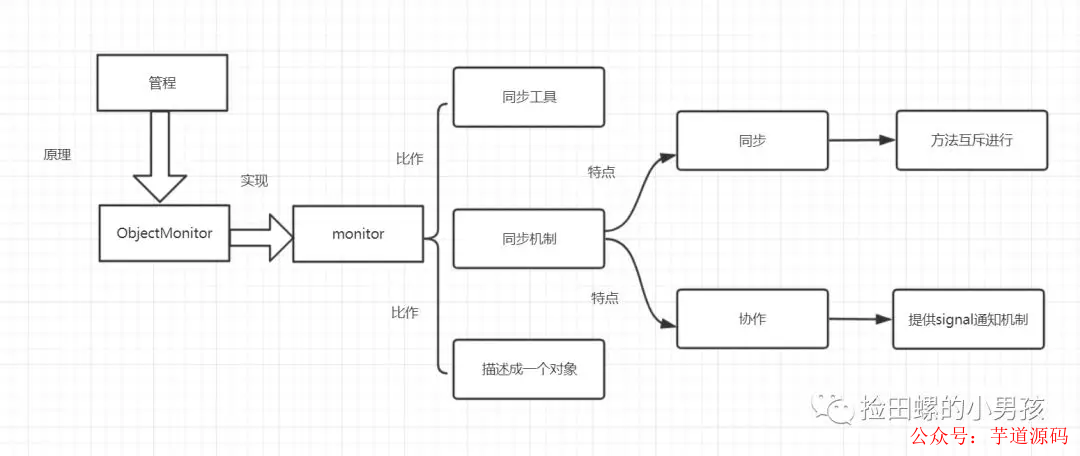
在Java虛擬機(HotSpot)中,Monitor(管程)是由ObjectMonitor實現的,其主要數據結構如下:
?
?
?ObjectMonitor()?{
????_header???????=?NULL;
????_count????????=?0;?//?記錄個數
????_waiters??????=?0,
????_recursions???=?0;
????_object???????=?NULL;
????_owner????????=?NULL;
????_WaitSet??????=?NULL;??//?處于wait狀態的線程,會被加入到_WaitSet
????_WaitSetLock??=?0?;
????_Responsible??=?NULL?;
????_succ?????????=?NULL?;
????_cxq??????????=?NULL?;
????FreeNext??????=?NULL?;
????_EntryList????=?NULL?;??//?處于等待鎖block狀態的線程,會被加入到該列表
????_SpinFreq?????=?0?;
????_SpinClock????=?0?;
????OwnerIsThread?=?0?;
??}
?
?
ObjectMonitor中幾個關鍵字段的含義如圖所示:
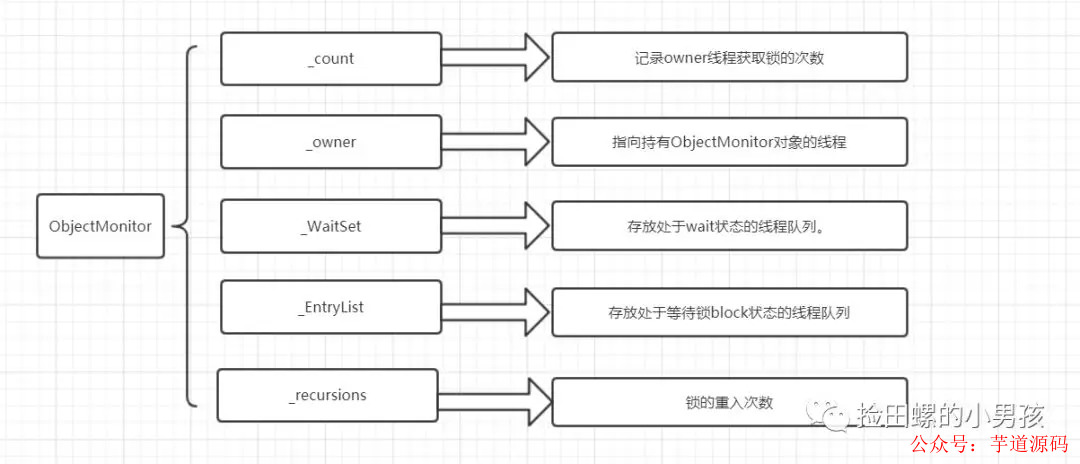
8.3 Java Monitor 的工作機理
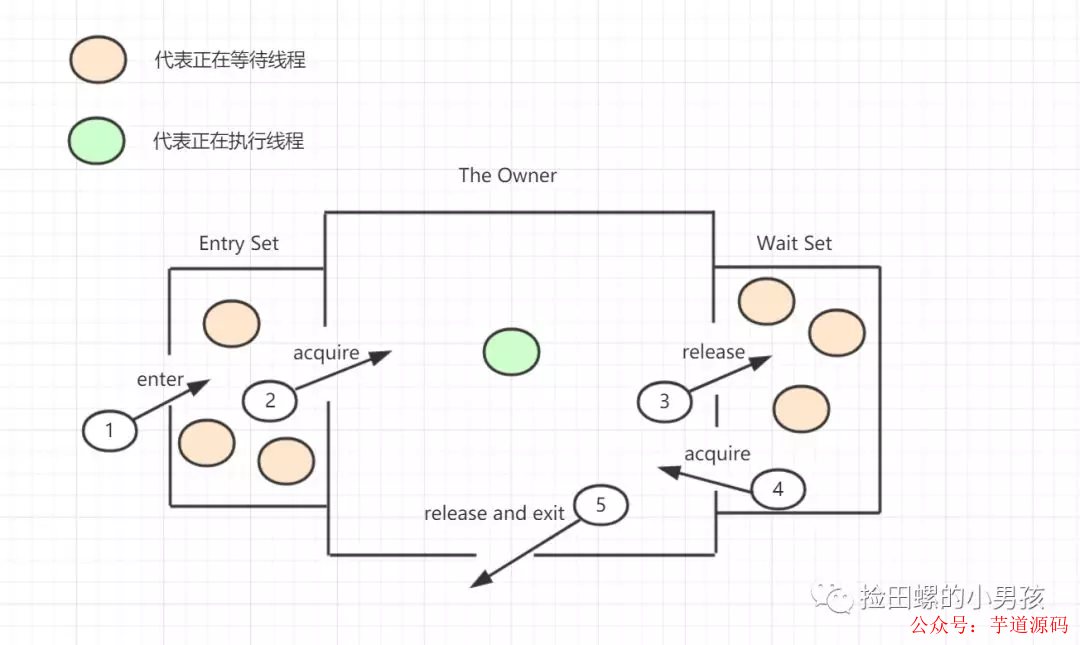
想要獲取monitor的線程,首先會進入_EntryList隊列。
當某個線程獲取到對象的monitor后,進入Owner區域,設置為當前線程,同時計數器count加1。
如果線程調用了wait()方法,則會進入WaitSet隊列。它會釋放monitor鎖,即將owner賦值為null,count自減1,進入WaitSet隊列阻塞等待。
如果其他線程調用 notify() / notifyAll() ,會喚醒WaitSet中的某個線程,該線程再次嘗試獲取monitor鎖,成功即進入Owner區域。
同步方法執行完畢了,線程退出臨界區,會將monitor的owner設為null,并釋放監視鎖。
8.4 對象與monitor關聯
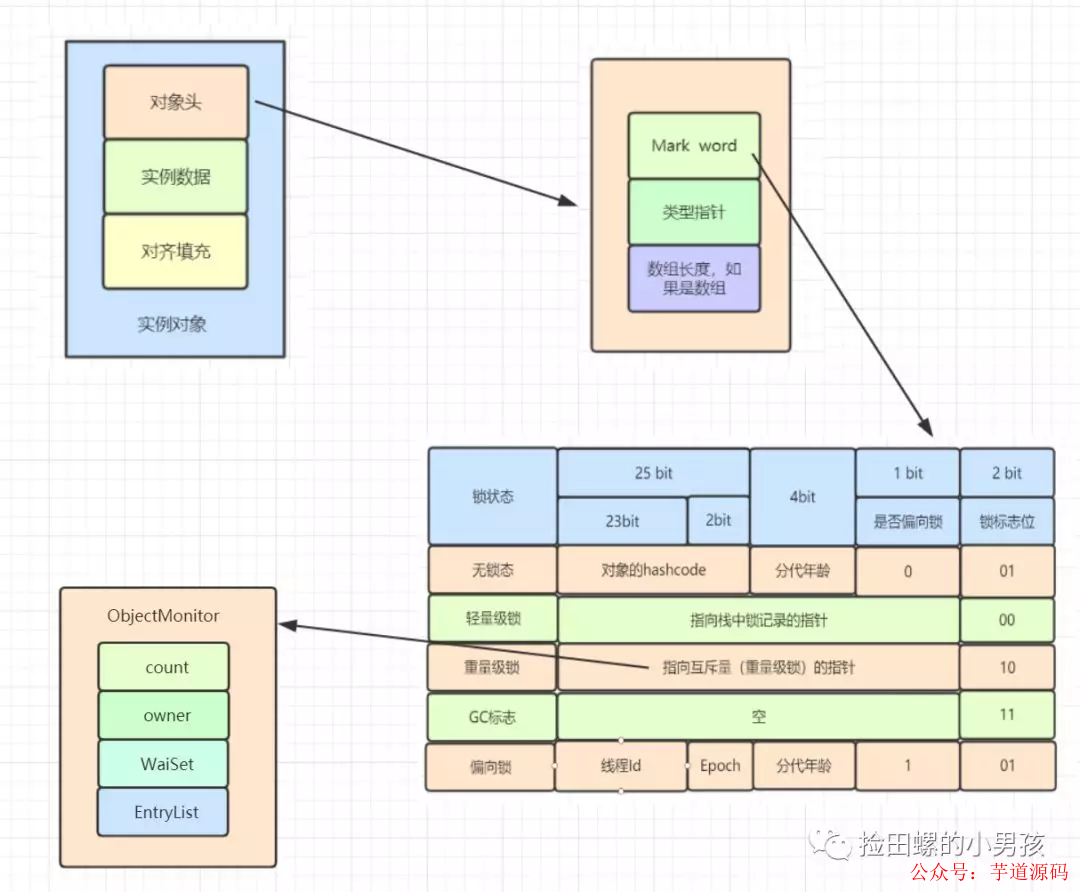
在HotSpot虛擬機中,對象在內存中存儲的布局可以分為3塊區域:對象頭(Header),實例數據(Instance Data)和對象填充(Padding) 。
對象頭主要包括兩部分數據:Mark Word(標記字段)、Class Pointer(類型指針) 。
Mark Word 是用于存儲對象自身的運行時數據,如哈希碼(HashCode)、GC分代年齡、鎖狀態標志、線程持有的鎖、偏向線程 ID、偏向時間戳等。
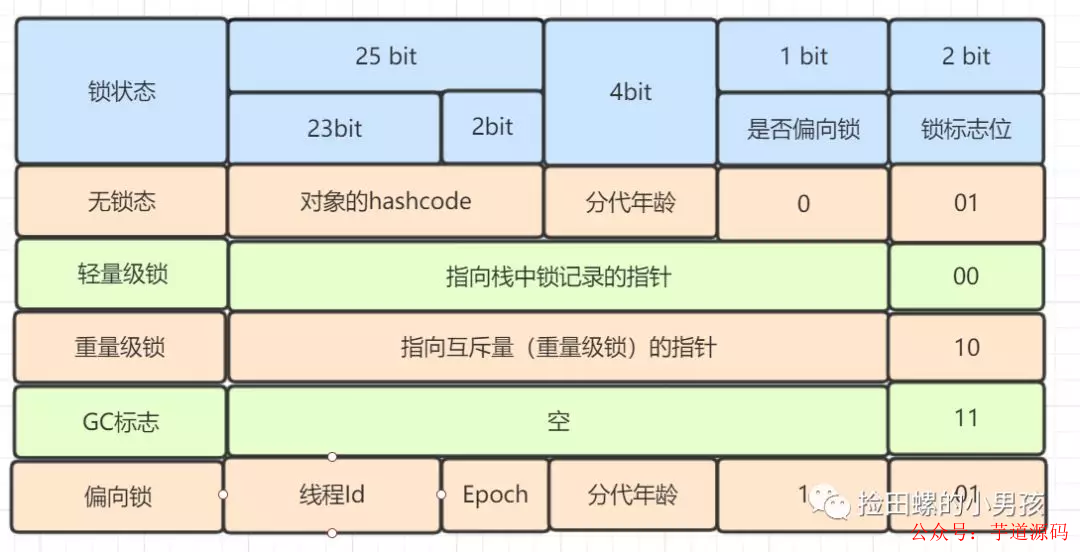
重量級鎖,指向互斥量的指針。其實synchronized是重量級鎖,也就是說Synchronized的對象鎖,Mark Word鎖標識位為10,其中指針指向的是Monitor對象的起始地址。
9. 線程有哪些狀態?
線程有6個狀態,分別是:New, Runnable, Blocked, Waiting, Timed_Waiting, Terminated。
轉換關系圖如下:
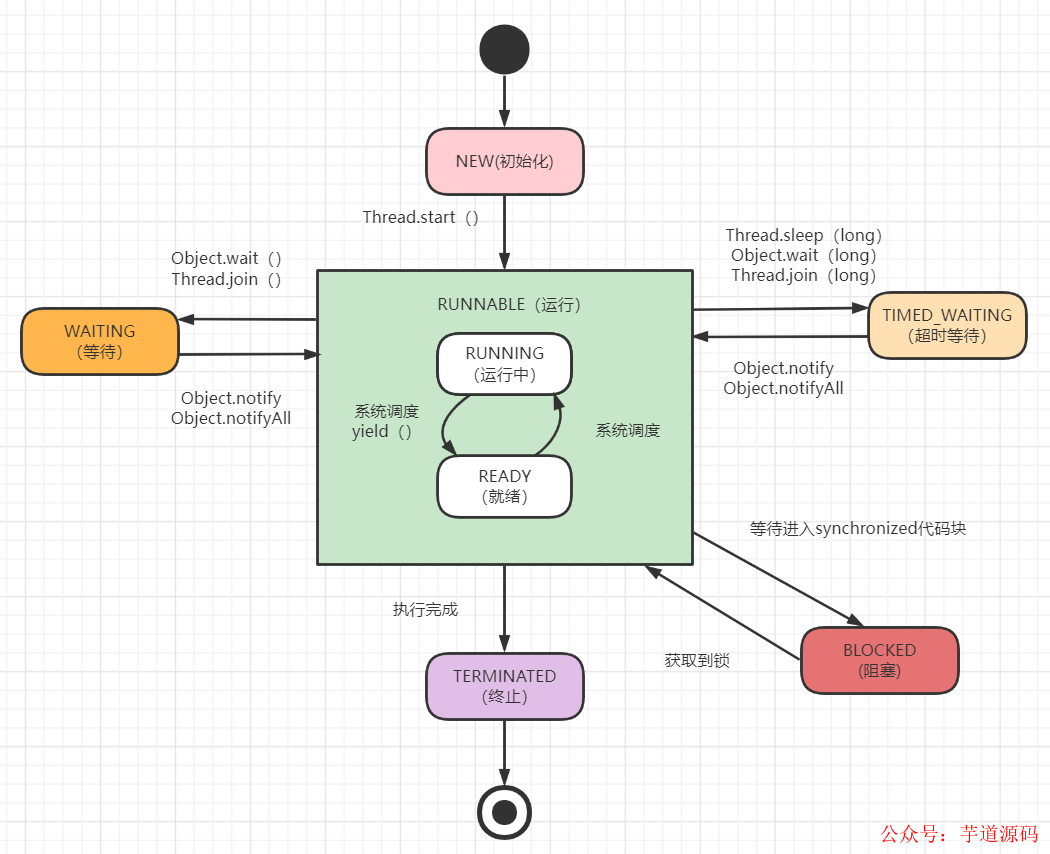
New:線程對象創建之后、但還沒有調用start()方法,就是這個狀態。
?
?
/**
?*?關注公眾號:芋道源碼
?*/
public?class?ThreadTest?{
????public?static?void?main(String[]?args)?{
????????Thread?thread?=?new?Thread();
????????System.out.println(thread.getState());
????}
}
//運行結果:
NEW
?
?
Runnable:它包括就緒(ready)和運行中(running)兩種狀態。如果調用start方法,線程就會進入Runnable狀態。它表示我這個線程可以被執行啦(此時相當于ready狀態),如果這個線程被調度器分配了CPU時間,那么就可以被執行(此時處于running狀態)。
?
?
public?class?ThreadTest?{
????public?static?void?main(String[]?args)?{
????????Thread?thread?=?new?Thread();
????????thread.start();
????????System.out.println(thread.getState());
????}
}
//運行結果:
RUNNABLE
?
?
Blocked:阻塞的(被同步鎖或者IO鎖阻塞)。表示線程阻塞于鎖,線程阻塞在進入synchronized關鍵字修飾的方法或代碼塊(等待獲取鎖 )時的狀態。比如前面有一個臨界區的代碼需要執行,那么線程就需要等待,它就會進入這個狀態。它一般是從RUNNABLE狀態轉化過來的。如果線程獲取到鎖,它將變成RUNNABLE狀態
?
?
Thread?t?=?new?Thread(new?Runnable?{
????void?run()?{
????????synchronized?(lock)?{?//?阻塞于這里,變為Blocked狀態
????????????//?dothings
????????}?
????}
});
t.getState();?//新建之前,還沒開始調用start方法,處于New狀態
t.start();?//調用start方法,就會進入Runnable狀態
?
?
WAITING : 永久等待狀態,進入該狀態的線程需要等待其他線程做出一些特定動作(比如通知)。處于該狀態的線程不會被分配CPU執行時間,它們要等待被顯式地喚醒,否則會處于無限期等待的狀態。一般Object.wait。
?
?
Thread?t?=?new?Thread(new?Runnable?{
????void?run()?{
????????synchronized?(lock)?{?//?Blocked
????????????//?dothings
????????????while?(!condition)?{
????????????????lock.wait();?//?into?Waiting
????????????}
????????}?
????}
});
t.getState();?//?New
t.start();?//?Runnable
?
?
TIMED_WATING: 等待指定的時間重新被喚醒的狀態。有一個計時器在里面計算的,最常見就是使用Thread.sleep方法觸發,觸發后,線程就進入了Timed_waiting狀態,隨后會由計時器觸發,再進入Runnable狀態。
?
?
Thread?t?=?new?Thread(new?Runnable?{
????void?run()?{
????????Thread.sleep(1000);?//?Timed_waiting
????}
});
t.getState();?//?New
t.start();?//?Runnable
?
?
終止(TERMINATED):表示該線程已經執行完成。
再來看個代碼demo吧:
?
?
/**
?*?關注公眾號:芋道源碼
?*/
public?class?ThreadTest?{
????private?static?Object?object?=?new?Object();
????public?static?void?main(String[]?args)?throws?Exception?{
????????Thread?thread?=?new?Thread(new?Runnable()?{
????????????@Override
????????????public?void?run()?{
????????????????try?{
????????????????????for(int?i?=?0;?i
?
?
10. synchronized 和 ReentrantLock 的區別?
Synchronized是依賴于JVM實現的,而ReenTrantLock是API實現的。
在Synchronized優化以前,synchronized的性能是比ReenTrantLock差很多的,但是自從Synchronized引入了偏向鎖,輕量級鎖(自旋鎖)后,兩者性能就差不多了。
Synchronized的使用比較方便簡潔,它由編譯器去保證鎖的加鎖和釋放。而ReenTrantLock需要手工聲明來加鎖和釋放鎖,最好在finally中聲明釋放鎖。
ReentrantLock可以指定是公平鎖還是?公平鎖。?synchronized只能是?公平鎖。
ReentrantLock可響應中斷、可輪回,而Synchronized是不可以響應中斷的
11. wait(),notify()和 suspend(), resume()之間的區別
wait()方法使得線程進入阻塞等待狀態,并且釋放鎖
notify()喚醒一個處于等待狀態的線程,它一般跟wait()方法配套使用。
suspend()使得線程進入阻塞狀態,并且不會自動恢復,必須對應的resume()被調用,才能使得線程重新進入可執行狀態。suspend()方法很容易引起死鎖問題。
resume()方法跟suspend()方法配套使用。
suspend()不建議使用 ,因為suspend()方法在調用后,線程不會釋放已經占有的資 源(比如鎖),而是占有著資源進入睡眠狀態,這樣容易引發死鎖問題。
12. CAS?CAS 有什么缺陷,如何解決?
CAS,全稱是Compare and Swap,翻譯過來就是比較并交換;
CAS涉及3個操作數,內存地址值V,預期原值A,新值B;如果內存位置的值V與預期原A值相匹配,就更新為新值B,否則不更新
CAS有什么缺陷?
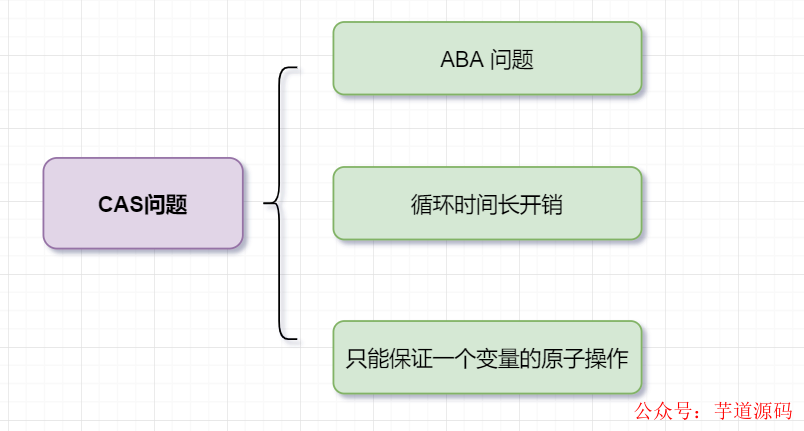
ABA 問題
并發環境下,假設初始條件是A,去修改數據時,發現是A就會執行修改。但是看到的雖然是A,中間可能發生了A變B,B又變回A的情況。此時A已經非彼A,數據即使成功修改,也可能有問題。
可以通過AtomicStampedReference 解決ABA問題 ,它,一個帶有標記的原子引用類,通過控制變量值的版本來保證CAS的正確性。
循環時間長開銷
自旋CAS,如果一直循環執行,一直不成功,會給CPU帶來非常大的執行開銷。很多時候,CAS思想體現,是有個自旋次數的,就是為了避開這個耗時問題~
只能保證一個變量的原子操作。
CAS 保證的是對一個變量執行操作的原子性,如果對多個變量操作時,CAS 目前無法直接保證操作的原子性的。可以通過這兩個方式解決這個問題:1. 使用互斥鎖來保證原子性;2.將多個變量封裝成對象,通過AtomicReference來保證原子性。
13. 說說CountDownLatch與 CyclicBarrier 區別
CountDownLatch和CyclicBarrier都用于讓線程等待,達到一定條件時再運行。主要區別是:
CountDownLatch:一個或者多個線程,等待其他多個線程完成某件事情之后才能執行;
CyclicBarrier:多個線程互相等待,直到到達同一個同步點,再繼續一起執行。
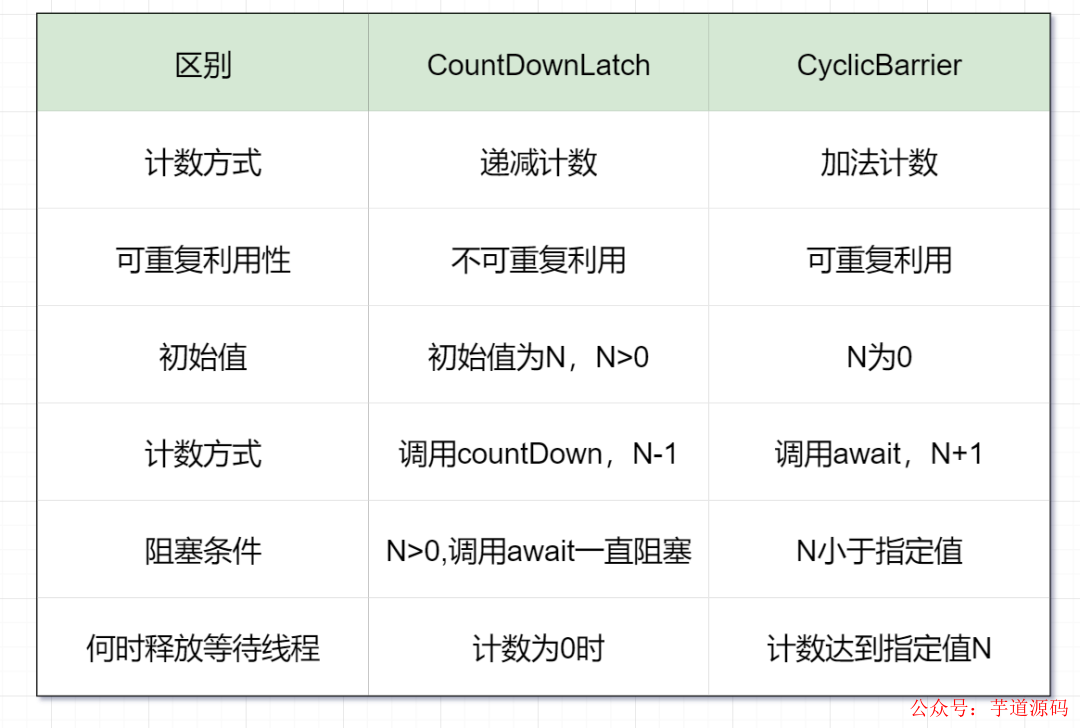
舉個例子吧:
CountDownLatch:假設老師跟同學約定周末在公園門口集合,等人齊了再發門票。那么,發門票(這個主線程),需要等各位同學都到齊(多個其他線程都完成),才能執行。
CyclicBarrier:多名短跑運動員要開始田徑比賽,只有等所有運動員準備好,裁判才會鳴槍開始,這時候所有的運動員才會疾步如飛。
14. 什么是多線程環境下的偽共享
14.1 什么是偽共享?
CPU的緩存是以緩存行(cache line)為單位進行緩存的,當多個線程修改相互獨立的變量,而這些變量又處于同一個緩存行時就會影響彼此的性能。這就是偽共享
現代計算機計算模型:
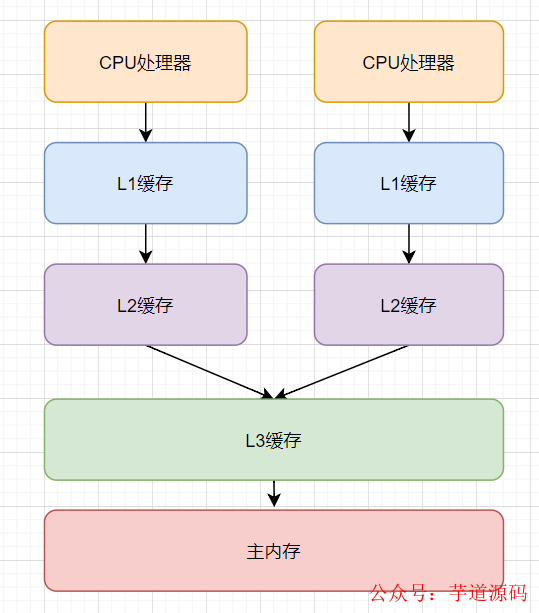
CPU執行速度比內存速度快好幾個數量級,為了提高執行效率,現代計算機模型演變出CPU、緩存(L1,L2,L3),內存的模型。
CPU執行運算時,如先從L1緩存查詢數據,找不到再去L2緩存找,依次類推,直到在內存獲取到數據。
為了避免頻繁從內存獲取數據,聰明的科學家設計出緩存行,緩存行大小為64字節。
也正是因為緩存行的存在 ,就導致了偽共享問題,如圖所示:
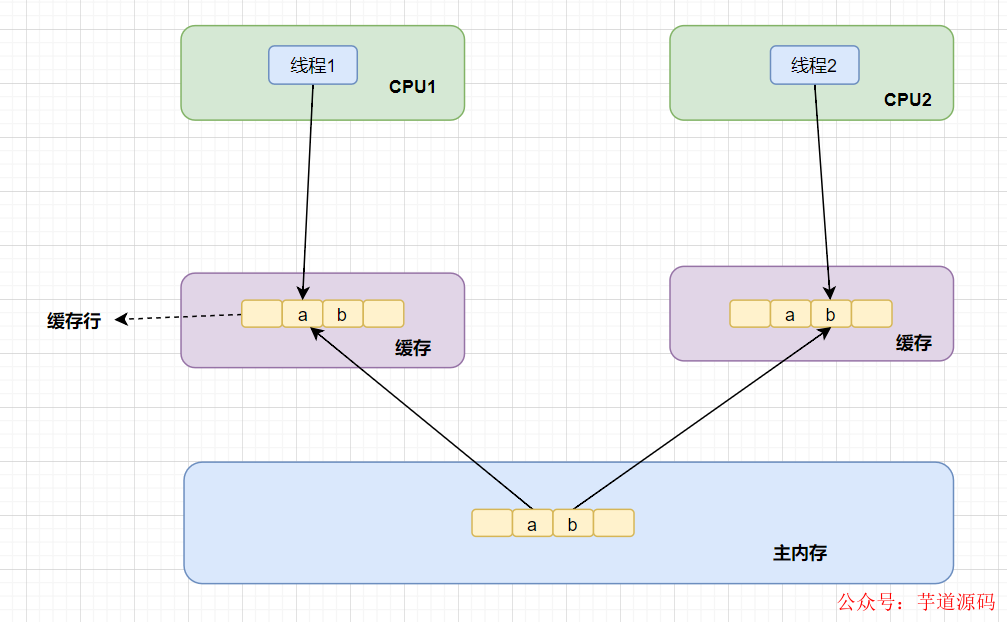
假設數據a、b被加載到同一個緩存行。
當線程1修改了a的值,這時候CPU1就會通知其他CPU核,當前緩存行(Cache line)已經失效。
這時候,如果線程2發起修改b,因為緩存行已經失效了,所以「core2 這時會重新從主內存中讀取該 Cache line 數據」。讀完后,因為它要修改b的值,那么CPU2就通知其他CPU核,當前緩存行(Cache line)又已經失效。
醬紫,如果同一個Cache line的內容被多個線程讀寫,就很容易產生相互競爭,頻繁回寫主內存,會大大降低性能。
14.2 如何解決偽共享問題
既然偽共享是因為相互獨立的變量存儲到相同的Cache line導致的,一個緩存行大小是64字節。那么,我們就可以使用空間換時間 的方法,即數據填充的方式 ,把獨立的變量分散到不同的Cache line~
來看個例子:
?
?
/**
?*?更多干貨內容,關注公眾號:芋道源碼
?*/
public?class?FalseShareTest??{
????public?static?void?main(String[]?args)?throws?InterruptedException?{
????????Rectangle?rectangle?=?new?Rectangle();
????????long?beginTime?=?System.currentTimeMillis();
????????Thread?thread1?=?new?Thread(()?->?{
????????????for?(int?i?=?0;?i??{
????????????for?(int?i?=?0;?i?
?
?
一個long類型是8字節,我們在變量a和b之間不上7個long類型變量呢,輸出結果是啥呢?如下:
?
?
class?Rectangle?{
????volatile?long?a;
????long?a1,a2,a3,a4,a5,a6,a7;
????volatile?long?b;
}
//運行結果
執行時間1113
?
?
可以發現利用填充數據的方式,讓讀寫的變量分割到不同緩存行,可以很好挺高性能~
15. Fork/Join框架的理解
Fork/Join框架是Java7提供的一個用于并行執行任務的框架,是一個把大任務分割成若干個小任務,最終匯總每個小任務結果后得到大任務結果的框架。
Fork/Join框架需要理解兩個點,「分而治之」和「工作竊取算法」。
分而治之
以上Fork/Join框架的定義,就是分而治之思想的體現啦
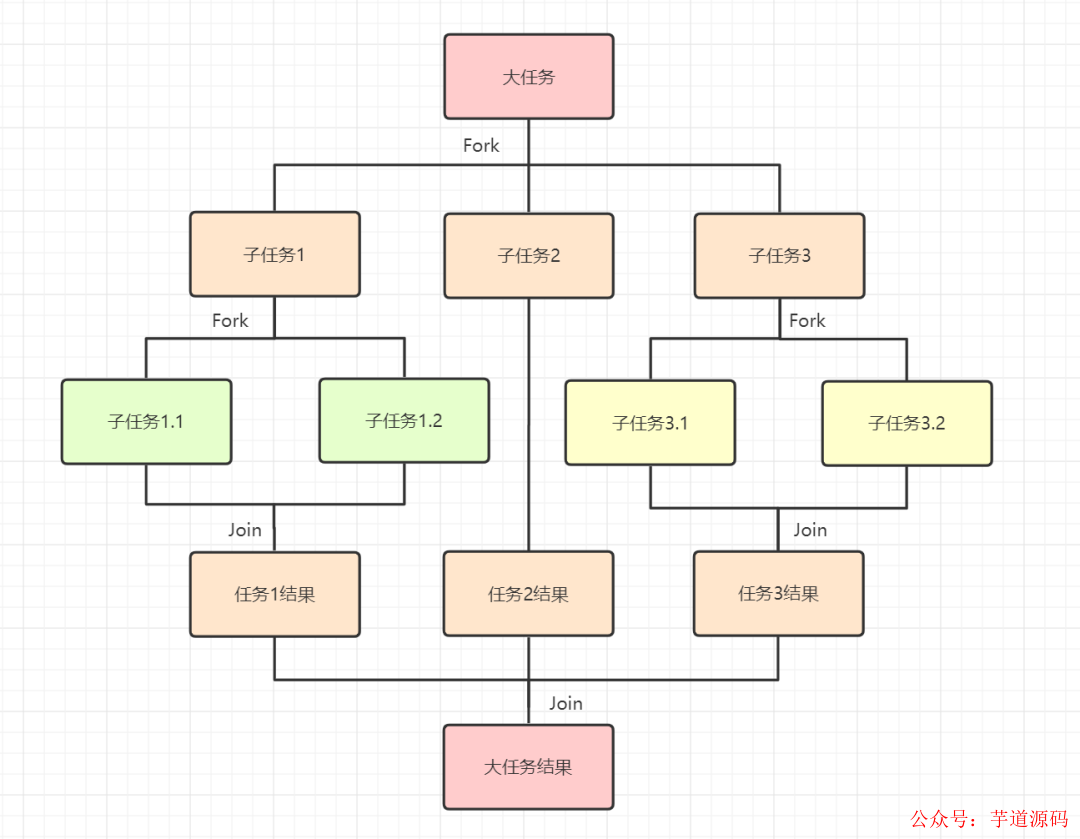
工作竊取算法
把大任務拆分成小任務,放到不同隊列執行,交由不同的線程分別執行時。有的線程優先把自己負責的任務執行完了,其他線程還在慢慢悠悠處理自己的任務,這時候為了充分提高效率,就需要工作盜竊算法啦~
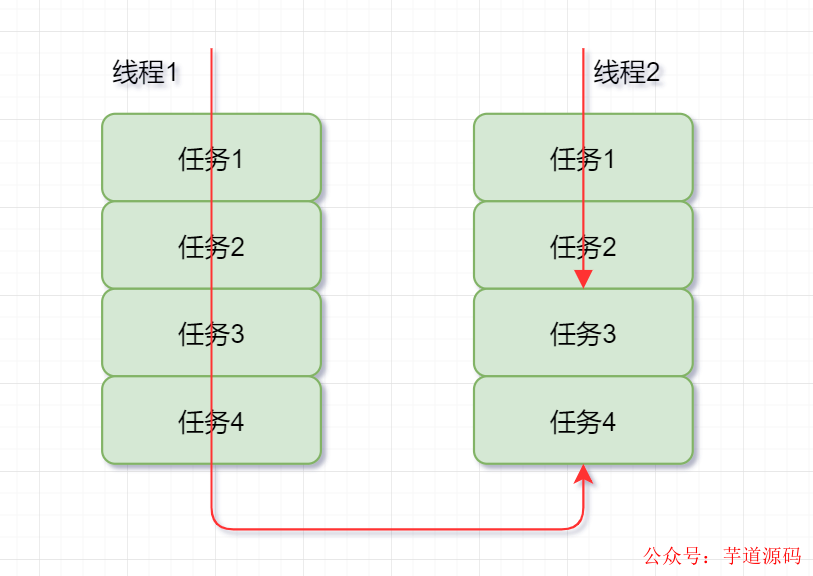
工作盜竊算法就是,「某個線程從其他隊列中竊取任務進行執行的過程」。一般就是指做得快的線程(盜竊線程)搶慢的線程的任務來做,同時為了減少鎖競爭,通常使用雙端隊列,即快線程和慢線程各在一端。
16. 聊聊ThreadLocal原理?
ThreadLocal的內存結構圖
為了對ThreadLocal有個宏觀的認識,我們先來看下ThreadLocal的內存結構圖
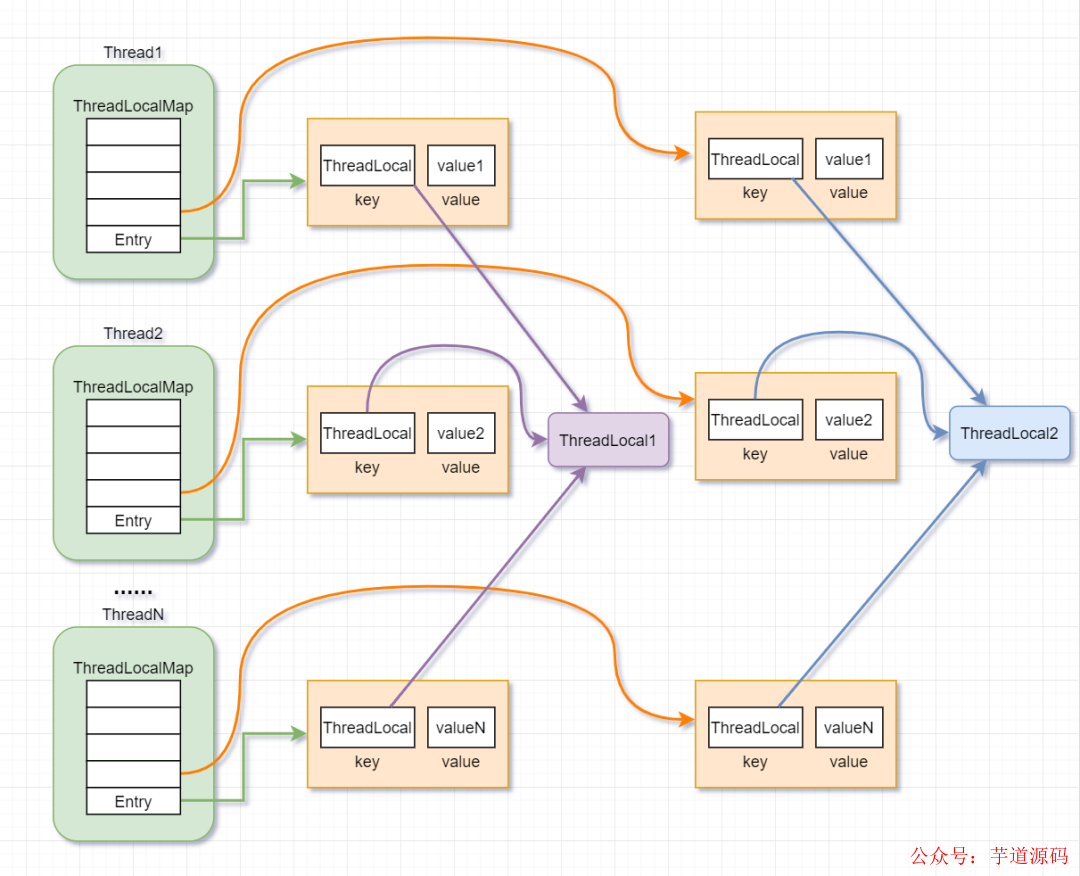
從內存結構圖,我們可以看到:
Thread類中,有個ThreadLocal.ThreadLocalMap 的成員變量。
ThreadLocalMap內部維護了Entry數組,每個Entry代表一個完整的對象,key是ThreadLocal本身,value是ThreadLocal的泛型對象值。
關鍵源碼分析
對照著關鍵源碼來看,更容易理解一點哈~
首先看下Thread類的源碼,可以看到成員變量ThreadLocalMap的初始值是為null
?
?
public?class?Thread?implements?Runnable?{
???//ThreadLocal.ThreadLocalMap是Thread的屬性
???ThreadLocal.ThreadLocalMap?threadLocals?=?null;
}
?
?
成員變量ThreadLocalMap的關鍵源碼如下:
?
?
static?class?ThreadLocalMap?{
????
????static?class?Entry?extends?WeakReference>?{
????????/**?The?value?associated?with?this?ThreadLocal.?*/
????????Object?value;
????????Entry(ThreadLocal?k,?Object?v)?{
????????????super(k);
????????????value?=?v;
????????}
????}
????//Entry數組
????private?Entry[]?table;
????
????//?ThreadLocalMap的構造器,ThreadLocal作為key
????ThreadLocalMap(ThreadLocal?firstKey,?Object?firstValue)?{
????????table?=?new?Entry[INITIAL_CAPACITY];
????????int?i?=?firstKey.threadLocalHashCode?&?(INITIAL_CAPACITY?-?1);
????????table[i]?=?new?Entry(firstKey,?firstValue);
????????size?=?1;
????????setThreshold(INITIAL_CAPACITY);
????}
}
?
?
ThreadLocal類中的關鍵set()方法:
?
?
?public?void?set(T?value)?{
????????Thread?t?=?Thread.currentThread();?//獲取當前線程t
????????ThreadLocalMap?map?=?getMap(t);??//根據當前線程獲取到ThreadLocalMap
????????if?(map?!=?null)??//如果獲取的ThreadLocalMap對象不為空
????????????map.set(this,?value);?//K,V設置到ThreadLocalMap中
????????else
????????????createMap(t,?value);?//創建一個新的ThreadLocalMap
????}
????
?????ThreadLocalMap?getMap(Thread?t)?{
???????return?t.threadLocals;?//返回Thread對象的ThreadLocalMap屬性
????}
????void?createMap(Thread?t,?T?firstValue)?{?//調用ThreadLocalMap的構造函數
????????t.threadLocals?=?new?ThreadLocalMap(this,?firstValue);?this表示當前類ThreadLocal
????}
????
?
?
ThreadLocal類中的關鍵get()方法
?
?
????public?T?get()?{
????????Thread?t?=?Thread.currentThread();//獲取當前線程t
????????ThreadLocalMap?map?=?getMap(t);//根據當前線程獲取到ThreadLocalMap
????????if?(map?!=?null)?{?//如果獲取的ThreadLocalMap對象不為空
????????????//由this(即ThreadLoca對象)得到對應的Value,即ThreadLocal的泛型值
????????????ThreadLocalMap.Entry?e?=?map.getEntry(this);
????????????if?(e?!=?null)?{
????????????????@SuppressWarnings("unchecked")
????????????????T?result?=?(T)e.value;?
????????????????return?result;
????????????}
????????}
????????return?setInitialValue();?//初始化threadLocals成員變量的值
????}
????
?????private?T?setInitialValue()?{
????????T?value?=?initialValue();?//初始化value的值
????????Thread?t?=?Thread.currentThread();?
????????ThreadLocalMap?map?=?getMap(t);?//以當前線程為key,獲取threadLocals成員變量,它是一個ThreadLocalMap
????????if?(map?!=?null)
????????????map.set(this,?value);??//K,V設置到ThreadLocalMap中
????????else
????????????createMap(t,?value);?//實例化threadLocals成員變量
????????return?value;
????}
?
?
所以怎么回答ThreadLocal的實現原理 ?如下,最好是能結合以上結構圖一起說明哈~
Thread線程類有一個類型為ThreadLocal.ThreadLocalMap的實例變量threadLocals,即每個線程都有一個屬于自己的ThreadLocalMap。
ThreadLocalMap內部維護著Entry數組,每個Entry代表一個完整的對象,key是ThreadLocal本身,value是ThreadLocal的泛型值。
并發多線程場景下,每個線程Thread,在往ThreadLocal里設置值的時候,都是往自己的ThreadLocalMap里存,讀也是以某個ThreadLocal作為引用,在自己的map里找對應的key,從而可以實現了線程隔離 。
17. TreadLocal為什么會導致內存泄漏呢?
弱引用導致的內存泄漏呢?
key是弱引用,GC回收會影響ThreadLocal的正常工作嘛?
ThreadLocal內存泄漏的demo
17.1 弱引用導致的內存泄漏呢?
我們先來看看TreadLocal的引用示意圖哈:
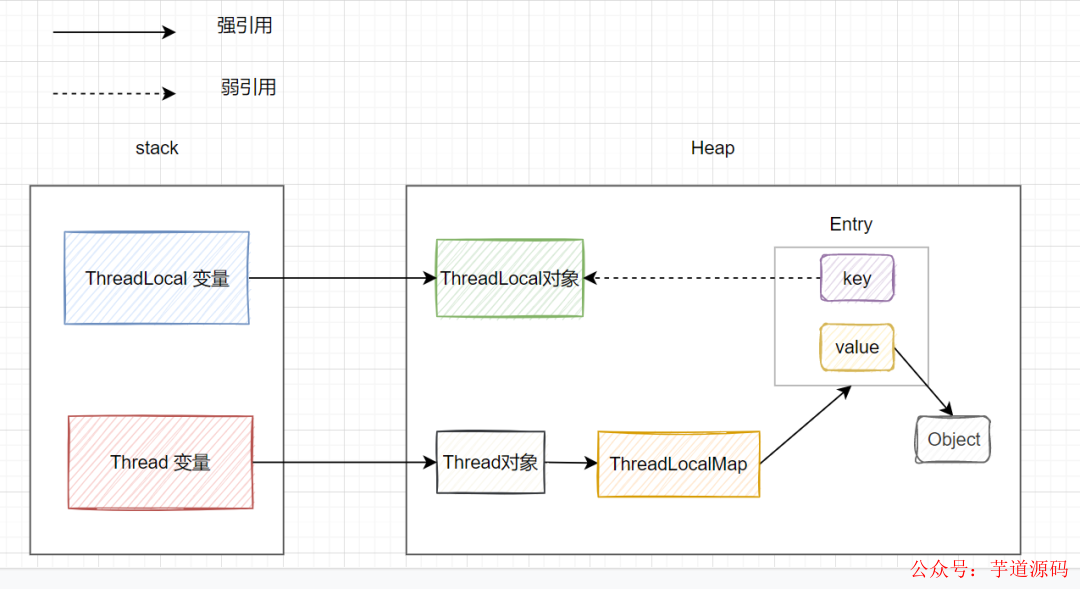
關于ThreadLocal內存泄漏,網上比較流行的說法是這樣的:
ThreadLocalMap使用ThreadLocal的弱引用 作為key,當ThreadLocal變量被手動設置為null,即一個ThreadLocal沒有外部強引用來引用它,當系統GC時,ThreadLocal一定會被回收。這樣的話,ThreadLocalMap中就會出現key為null的Entry,就沒有辦法訪問這些key為null的Entry的value,如果當前線程再遲遲不結束的話(比如線程池的核心線程),這些key為null的Entry的value就會一直存在一條強引用鏈:Thread變量 -> Thread對象 -> ThreaLocalMap -> Entry -> value -> Object 永遠無法回收,造成內存泄漏。
當ThreadLocal變量被手動設置為null后的引用鏈圖:
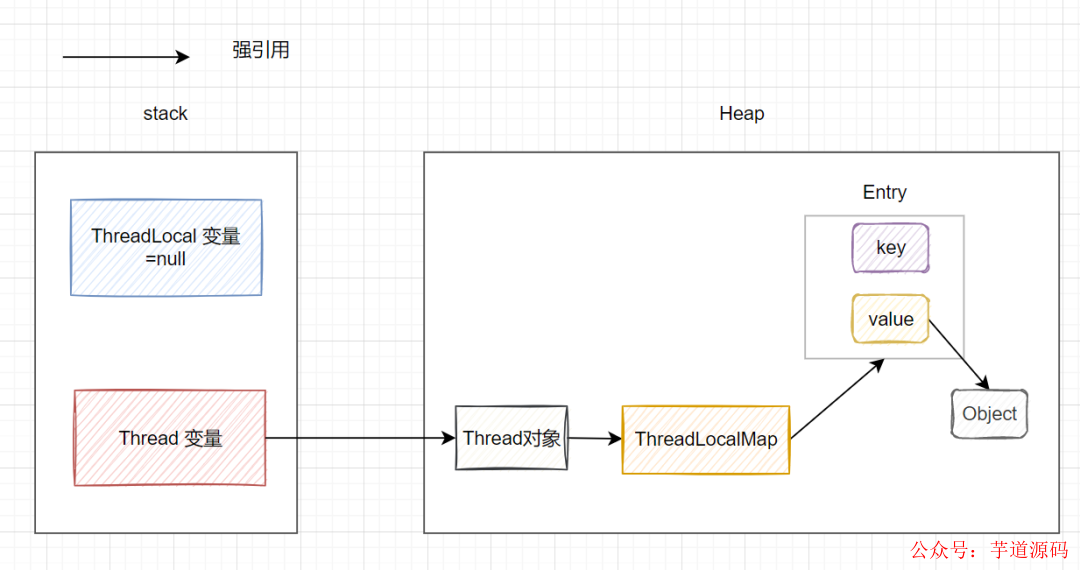
實際上,ThreadLocalMap的設計中已經考慮到這種情況。所以也加上了一些防護措施:即在ThreadLocal的get,set,remove方法,都會清除線程ThreadLocalMap里所有key為null的value。
源代碼中,是有體現的,如ThreadLocalMap的set方法:
?
?
??private?void?set(ThreadLocal?key,?Object?value)?{
??????Entry[]?tab?=?table;
??????int?len?=?tab.length;
??????int?i?=?key.threadLocalHashCode?&?(len-1);
??????for?(Entry?e?=?tab[i];
????????????e?!=?null;
????????????e?=?tab[i?=?nextIndex(i,?len)])?{
??????????ThreadLocal?k?=?e.get();
??????????if?(k?==?key)?{
??????????????e.value?=?value;
??????????????return;
??????????}
???????????//如果k等于null,則說明該索引位之前放的key(threadLocal對象)被回收了,這通常是因為外部將threadLocal變量置為null,
???????????//又因為entry對threadLocal持有的是弱引用,一輪GC過后,對象被回收。
????????????//這種情況下,既然用戶代碼都已經將threadLocal置為null,那么也就沒打算再通過該對象作為key去取到之前放入threadLocalMap的value,?因此ThreadLocalMap中會直接替換調這種不新鮮的entry。
??????????if?(k?==?null)?{
??????????????replaceStaleEntry(key,?value,?i);
??????????????return;
??????????}
????????}
????????tab[i]?=?new?Entry(key,?value);
????????int?sz?=?++size;
????????//觸發一次Log2(N)復雜度的掃描,目的是清除過期Entry??
????????if?(!cleanSomeSlots(i,?sz)?&&?sz?>=?threshold)
??????????rehash();
????}
?
?
如ThreadLocal的get方法:
?
?
??public?T?get()?{
????Thread?t?=?Thread.currentThread();
????ThreadLocalMap?map?=?getMap(t);
????if?(map?!=?null)?{
????????//去ThreadLocalMap獲取Entry,方法里面有key==null的清除邏輯
????????ThreadLocalMap.Entry?e?=?map.getEntry(this);
????????if?(e?!=?null)?{
????????????@SuppressWarnings("unchecked")
????????????T?result?=?(T)e.value;
????????????return?result;
????????}
????}
????return?setInitialValue();
}
private?Entry?getEntry(ThreadLocal?key)?{
????????int?i?=?key.threadLocalHashCode?&?(table.length?-?1);
????????Entry?e?=?table[i];
????????if?(e?!=?null?&&?e.get()?==?key)
?????????????return?e;
????????else
??????????//里面有key==null的清除邏輯
??????????return?getEntryAfterMiss(key,?i,?e);
????}
????????
private?Entry?getEntryAfterMiss(ThreadLocal?key,?int?i,?Entry?e)?{
????????Entry[]?tab?=?table;
????????int?len?=?tab.length;
????????while?(e?!=?null)?{
????????????ThreadLocal?k?=?e.get();
????????????if?(k?==?key)
????????????????return?e;
????????????//?Entry的key為null,則表明沒有外部引用,且被GC回收,是一個過期Entry
????????????if?(k?==?null)
????????????????expungeStaleEntry(i);?//刪除過期的Entry
????????????else
????????????????i?=?nextIndex(i,?len);
????????????e?=?tab[i];
????????}
????????return?null;
????}
?
?
17.2 key是弱引用,GC回收會影響ThreadLocal的正常工作嘛?
有些小伙伴可能有疑問,ThreadLocal的key既然是弱引用 .會不會GC貿然把key回收掉,進而影響ThreadLocal的正常使用?
弱引用 :具有弱引用的對象擁有更短暫的生命周期。如果一個對象只有弱引用存在了,則下次GC將會回收掉該對象 (不管當前內存空間足夠與否)
其實不會的,因為有ThreadLocal變量引用著它,是不會被GC回收的,除非手動把ThreadLocal變量設置為null,我們可以跑個demo來驗證一下:
?
?
??public?class?WeakReferenceTest?{
????public?static?void?main(String[]?args)?{
????????Object?object?=?new?Object();
????????WeakReference  電子發燒友App
電子發燒友App

