

本文介紹了本小組發(fā)表于EMNLP2022 Industry Track的論文SimANS,其設(shè)計了一簡單有效的通用困惑負(fù)樣本采樣方法,在5個數(shù)據(jù)集上提升了SOTA的稠密檢索模型的效果。
論文下載地址:https://arxiv.org/pdf/2210.11773.pdf
論文開源代碼:https://github.com/microsoft/SimXNS
前言
在各類檢索任務(wù)中,為訓(xùn)練好一個高質(zhì)量的檢索模型,往往需要從大量的候選樣本集合中采樣高質(zhì)量的負(fù)例,配合正例一起進(jìn)行訓(xùn)練。已有的負(fù)采樣方法往往采用隨機(jī)采樣策略(Random Sampling)或直接基于該檢索模型自身選擇Top-K負(fù)例(Top-K Hard Negative Sampling),前者易得到過于簡單的樣例,無法為模型訓(xùn)練提供足夠信息;后者很可能采樣得到假負(fù)例(False Negative),反而干擾模型訓(xùn)練。本文針對稠密檢索場景,通過一系列基于負(fù)例梯度的實驗對隨機(jī)采樣和Top-K采樣兩種方式導(dǎo)致的問題進(jìn)行分析,發(fā)現(xiàn)前一種負(fù)例產(chǎn)生的梯度均值較小、后一種負(fù)例產(chǎn)生的梯度方差較大,這兩者都不利于檢索模型訓(xùn)練。此外,以上實驗還發(fā)現(xiàn),在所有負(fù)例候選中,與Query的語義相似度接近于正例的負(fù)例可以同時具有較大的梯度均值和較小的梯度方差,是更加高質(zhì)量的困惑負(fù)樣本。因此我們設(shè)計了一個簡單的困惑負(fù)樣本采樣方法SimANS,在4個篇章和文檔檢索數(shù)據(jù)集,以及Bing真實數(shù)據(jù)集上均成功提升了SOTA模型的效果,且該方法已經(jīng)應(yīng)用于Bing搜索系統(tǒng)。
一、研究背景與動機(jī)
1、稠密檢索
給出用戶的查詢Query,檢索任務(wù)關(guān)注于從大量的候選文檔集中檢索最相關(guān)的Top-K文檔。隨著近年來文本表示方法的發(fā)展,稠密檢索任務(wù)開始成為該任務(wù)的主流方法,其通常采用一雙塔模型架構(gòu),分別將查詢Query和候選Document轉(zhuǎn)換成低維的稠密表示,然后基于Query和Document稠密表示的點積來預(yù)測兩者的語義相關(guān)性,并依此進(jìn)行候選文檔的排序。這一計算方式支持ANN等方法加速,故可以推廣到千萬級別文檔的查詢。
近年來,由于預(yù)訓(xùn)練語言模型的出現(xiàn),已有的稠密檢索方法往往采用預(yù)訓(xùn)練語言模型作為Query和Document的Encoder,然后將其編碼后生成的[CLS]表示作為其稠密表示。
2、負(fù)采樣方法
為訓(xùn)練該稠密檢索模型,已有方法通常基于一對比學(xué)習(xí)訓(xùn)練目標(biāo),即拉近語義一致的Query和Document的表示(Positive),并推遠(yuǎn)語義無關(guān)的Document(Negative)。由于在大量的候選文檔集中,大量的文檔都是語義無關(guān)的,故需要采用一合適的負(fù)采樣方法,從中選擇高質(zhì)量的負(fù)例來進(jìn)行訓(xùn)練,依此減少需要的負(fù)樣本數(shù)量。
2.1.隨機(jī)負(fù)采樣
該類方法直接基于一均勻分布從所有的候選Document中隨機(jī)抽取Document作為負(fù)例,這一過程中由于無法保證采樣得到的負(fù)例的質(zhì)量,故經(jīng)常會采樣得到過于簡單的負(fù)例,其不僅無法給模型帶來有用信息,還可能導(dǎo)致模型過擬合,進(jìn)而無法區(qū)分某些較難的負(fù)例樣本。
2.2.Top-K負(fù)采樣
該類方法往往基于一稠密檢索模型對所有候選Document與Query計算匹配分?jǐn)?shù),然后直接選擇其中Top-K的候選Document作為負(fù)例。該方法雖然可以保證采樣得到的負(fù)例是模型未能較好區(qū)分的較難負(fù)例,但是其很可能將潛在的正例也誤判為負(fù)例,即假負(fù)例(False Negative)。如果訓(xùn)練模型去將該部分假負(fù)例與正例區(qū)分開來,反而會導(dǎo)致模型無法準(zhǔn)確衡量Query-Document的語義相似度。
二、先導(dǎo)實驗
1、理論分析不同負(fù)例訓(xùn)練時對梯度的影響
以稠密檢索常用的BCE loss為例,正例與采樣的負(fù)例在計算完語義相似度分?jǐn)?shù)后,均會被softmax歸一化,之后計算得到的梯度如下所示:
上式中是經(jīng)過softmax歸一化后的語義相似度分?jǐn)?shù)。對于隨機(jī)采樣方法,由于其采樣得到的負(fù)例往往過于簡單,其會導(dǎo)致該分?jǐn)?shù)接近于零,,進(jìn)而導(dǎo)致其生成的梯度均值也接近于零,,這樣過于小的梯度均值會導(dǎo)致模型不易于收斂。對于Top-K采樣方法,由于其很容易采樣得到語義與正例一致的假負(fù)例,其會導(dǎo)致正負(fù)樣本的右項值相似,但是左項符號相反,這樣會導(dǎo)致計算得到的梯度方差很大,同樣導(dǎo)致模型訓(xùn)練不穩(wěn)定。
2、實驗驗證不同負(fù)例的梯度與語義相似度關(guān)系
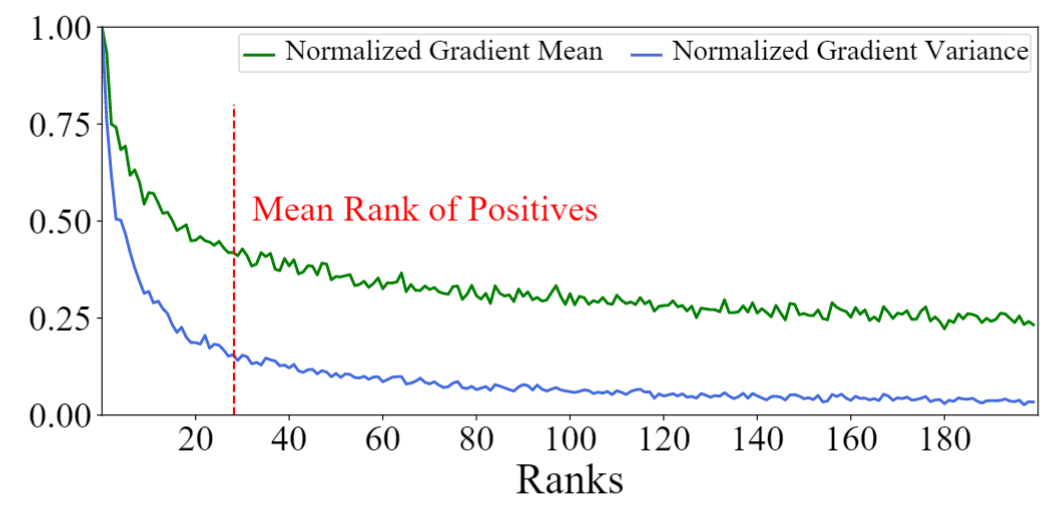
我們基于SOTA的稠密檢索模型AR2,在MS-MARCO數(shù)據(jù)集上,首先計算候選Document與Query的語義相似度分?jǐn)?shù),然后將這些Document進(jìn)行排序,并計算其梯度的均值與方差。如下圖所示,我們可以看到實驗結(jié)論與以上分析一致,排名靠前的Top-K負(fù)例產(chǎn)生的梯度均值和方差均很大;而排名靠后的負(fù)例產(chǎn)生的均值和方差均很小,兩者不能很好的平衡大均值和小方差這兩個很重要的負(fù)例性質(zhì)。作為對比的是,與正例語義相似度接近的負(fù)例往往能夠同時取得較大的梯度均值和較小的梯度方差,有利于模型訓(xùn)練。我們將其命名為困惑樣本(既不過于難又不過于容易區(qū)分),并關(guān)注于對其進(jìn)行采樣。
三、SimANS:簡單的困惑樣本采樣方法
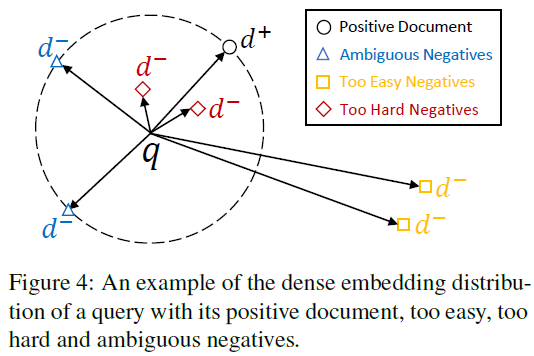
基于上述實驗,我們考慮對與正例語義相似度接近的困惑負(fù)例樣本進(jìn)行采樣。故設(shè)計的采樣方法應(yīng)該具有以下特點:(1)與Query無關(guān)的Document應(yīng)被賦予較低的相關(guān)分?jǐn)?shù),因其可提供的信息量不足;(2)與Query很可能相關(guān)的Document應(yīng)被賦予較低的相關(guān)分?jǐn)?shù),因其可能是假負(fù)例;(3)與正例語義相似度接近的Document應(yīng)該被賦予較高的相關(guān)分?jǐn)?shù),因其既需要被學(xué)習(xí),同時是假負(fù)例的概率相對較低。
困惑樣本采樣分布
通過以上分析可得,在該采樣分布中,隨著Query與候選Document相關(guān)分?jǐn)?shù)和與正例的相關(guān)分?jǐn)?shù)的差值的縮小,該候選Document被采樣作為負(fù)例的概率應(yīng)該逐漸增大,故可將該差值作為輸入,配合任意一單調(diào)遞減函數(shù)即可實現(xiàn)(如)。故可設(shè)計采樣分布如下所示:
其中為控制該分布密度的超參數(shù),為控制該分布極值點的超參數(shù),是一隨機(jī)采樣的正例樣本,是Top-K的負(fù)例。通過調(diào)節(jié)K的大小,我們可以控制該采樣分布的計算開銷。以下為該采樣方法具體實現(xiàn)的偽代碼:

四、實驗結(jié)果
1、主實驗
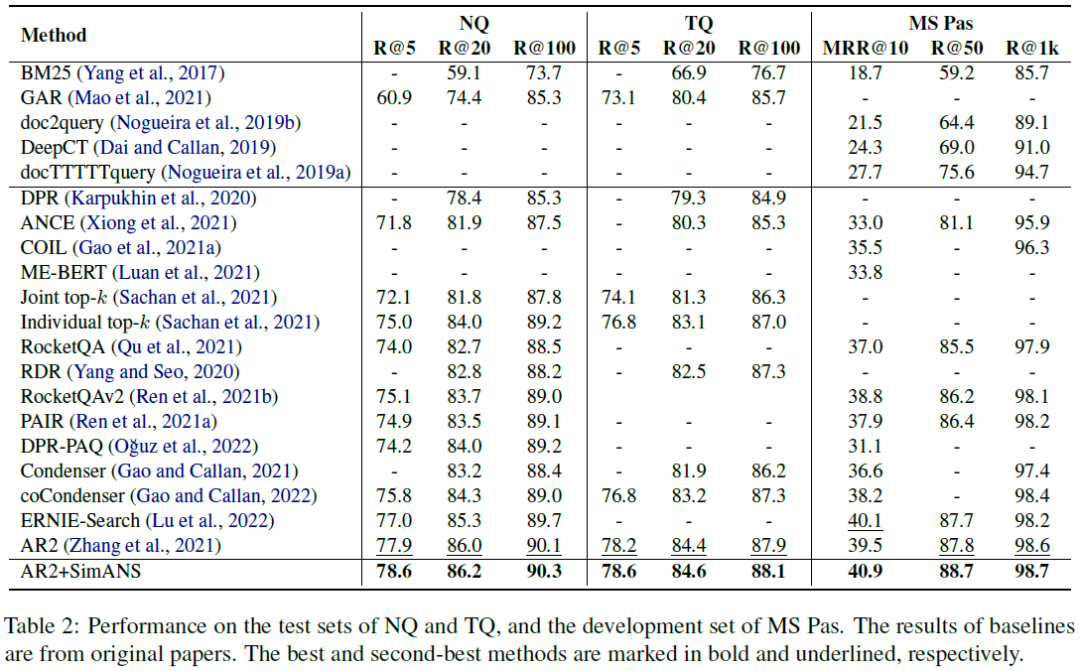
我們在4個公開的文檔檢索數(shù)據(jù)集上進(jìn)行實驗,分別是Natural Question(NQ)、Trivia QA(TQ)、MS-MARCO Passage Ranking(MS-Pas)和MS-MARCO Document Ranking(MS-Doc)數(shù)據(jù)集;同時還在Bing真實工業(yè)數(shù)據(jù)集上進(jìn)行實驗,實驗結(jié)果如下表所示。通過對比可以清晰地看出我們的方法可以提升SOTA的AR2模型的效果,進(jìn)一步領(lǐng)先其他模型。
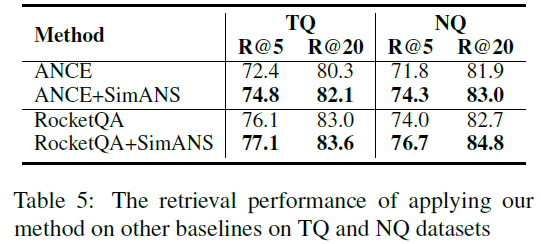
2、該負(fù)采樣方法的通用性
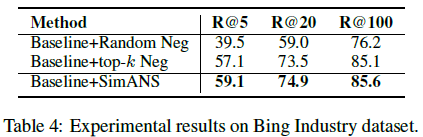
我們還在RocketQA和ANCE這兩個經(jīng)典的稠密檢索模型上實現(xiàn)了我們提出的SimANS方法,來提升這些模型的性能。可以看出,在采用該方法之后,以上兩個模型的的表現(xiàn)都超過了原始模型,證明了我們提出的方法的通用性。
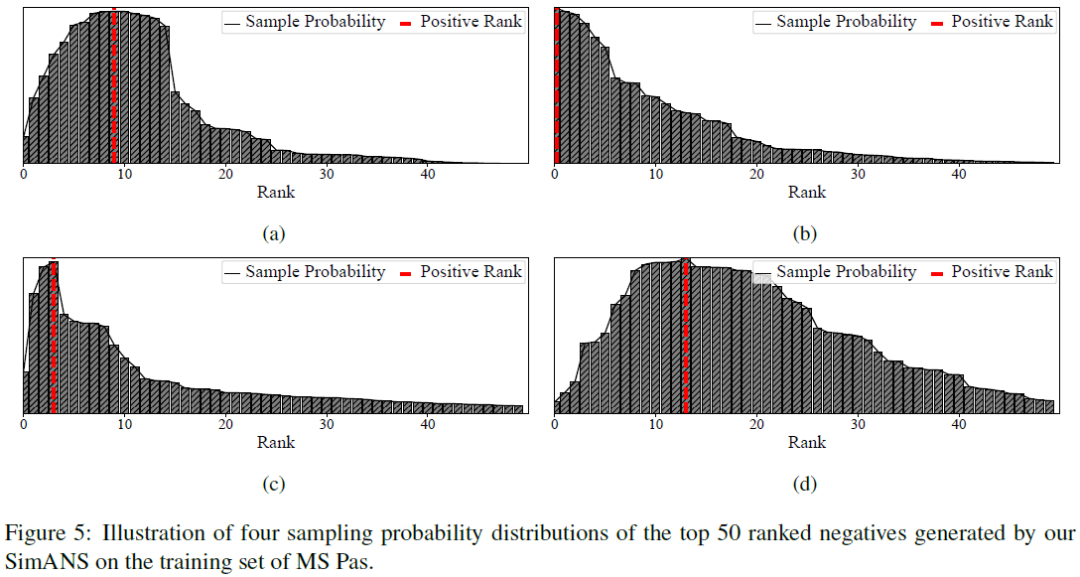
3、負(fù)采樣分布的可視化
在實驗的最后,我們將SimANS得到的采樣分布制作成圖,可以看到我們的采樣分布函數(shù)確實能夠懲罰過于難和過于簡單的負(fù)例,并保證與正例的語義相似度接近的負(fù)例的采樣概率較大。實現(xiàn)了我們的設(shè)計初衷。
審核編輯 :李倩
-
參數(shù)
+關(guān)注
關(guān)注
11文章
1866瀏覽量
32851 -
語言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10659 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25268
原文標(biāo)題:EMNLP2022 | SimANS:簡單有效的困惑負(fù)樣本采樣方法
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
機(jī)器學(xué)習(xí)的5種采樣方法介紹
PCB接地設(shè)計寶典4:采樣時鐘考量和混合信號接地的困惑根源
怎么使用UART向PC發(fā)送數(shù)字樣本
一種先分割后分類的兩階段同步端到端缺陷檢測方法
測量功率二極管的反向恢復(fù)時間簡單有效方法
什么是采樣頻率?什么叫采樣頻率

入侵檢測樣本數(shù)據(jù)優(yōu)化方法
經(jīng)典的采樣方法有哪些?
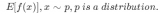
基于構(gòu)造性覆蓋算法的過采樣技術(shù)CMOTE

一種從患者血液樣本中有效分離異質(zhì)性CTCs的簡單、廣譜的方法
基于有效樣本的類別不平衡損失

融合零樣本學(xué)習(xí)和小樣本學(xué)習(xí)的弱監(jiān)督學(xué)習(xí)方法綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論