


這份終極指南從簡(jiǎn)單到復(fù)雜,一步步教你清除模型中所有的GP模型,直到你可以完成的大多數(shù)PITA修改,以充分利用你的網(wǎng)絡(luò)。
事實(shí)上,你的模型可能還停留在石器時(shí)代的水平。估計(jì)你還在用32位精度或GASP(一般活動(dòng)仿真語(yǔ)言)訓(xùn)練,甚至可能只在單GPU上訓(xùn)練。如果市面上有99個(gè)加速指南,但你可能只看過1個(gè)?(沒錯(cuò),就是這樣)。但這份終極指南,會(huì)一步步教你清除模型中所有的(GP模型)。
這份指南的介紹從簡(jiǎn)單到復(fù)雜,一直介紹到你可以完成的大多數(shù)PITA修改,以充分利用你的網(wǎng)絡(luò)。例子中會(huì)包括一些Pytorch代碼和相關(guān)標(biāo)記,可以在 Pytorch-Lightning訓(xùn)練器中用,以防大家不想自己敲碼!
這份指南針對(duì)的是誰(shuí)? 任何用Pytorch研究非瑣碎的深度學(xué)習(xí)模型的人,比如工業(yè)研究人員、博士生、學(xué)者等等……這些模型可能要花費(fèi)幾天,甚至幾周、幾個(gè)月的時(shí)間來訓(xùn)練。
本文涵蓋以下內(nèi)容(從易到難):
- 使用DataLoader
- DataLoader中的進(jìn)程數(shù)
- 批尺寸
- 累積梯度
- 保留計(jì)算圖
- 轉(zhuǎn)至單GPU
- 16位混合精度訓(xùn)練
- 轉(zhuǎn)至多GPU(模型復(fù)制)
- 轉(zhuǎn)至多GPU節(jié)點(diǎn)(8+GPUs)
- 有關(guān)模型加速的思考和技巧
Pytorch-Lightning
文中討論的各種優(yōu)化,都可以在Pytorch-Lightning找到:https://github.com/williamFalcon/pytorch-lightning?source=post_page
Lightning是基于Pytorch的一個(gè)光包裝器,它可以幫助研究人員自動(dòng)訓(xùn)練模型,但關(guān)鍵的模型部件還是由研究人員完全控制。
參照此篇教程,獲得更有力的范例:https://github.com/williamFalcon/pytorch-lightning/blob/master/examples/new_project_templates/single_gpu_node_template.py?source=post_page
Lightning采用最新、最尖端的方法,將犯錯(cuò)的可能性降到最低。
MNIST定義的Lightning模型可適用于訓(xùn)練器:https://github.com/williamFalcon/pytorch-lightning/blob/master/examples/new_project_templates/lightning_module_template.py?source=post_page
frompytorch-lightningimportTrainer
model=LightningModule(…)
trainer=Trainer()
trainer.fit(model)
1. DataLoader
這可能是最容易提速的地方。靠保存h5py或numpy文件來加速數(shù)據(jù)加載的日子已經(jīng)一去不復(fù)返了。用 Pytorch dataloader 加載圖像數(shù)據(jù)非常簡(jiǎn)單:https://pytorch.org/tutorials/beginner/data_loading_tutorial.html?source=post_page
關(guān)于NLP數(shù)據(jù),請(qǐng)參照TorchText:https://torchtext.readthedocs.io/en/latest/datasets.html?source=post_page
dataset=MNIST(root=self.hparams.data_root,train=train,download=True)
loader=DataLoader(dataset,batch_size=32,shuffle=True)
forbatchinloader:
x,y=batch
model.training_step(x,y)
...
在Lightning中,你無需指定一個(gè)訓(xùn)練循環(huán),只需定義dataLoaders,訓(xùn)練器便會(huì)在需要時(shí)調(diào)用它們。
2. DataLoaders中的進(jìn)程數(shù)
加快速度的第二個(gè)秘訣在于允許批量并行加載。所以,你可以一次加載許多批量,而不是一次加載一個(gè)。
#slow
loader=DataLoader(dataset,batch_size=32,shuffle=True)
#fast(use10workers)
loader=DataLoader(dataset,batch_size=32,shuffle=True,num_workers=10)
3. 批量大小(Batch size)
在開始下一步優(yōu)化步驟之前,將批量大小調(diào)高到CPU內(nèi)存或GPU內(nèi)存允許的最大值。
接下來的部分將著重于減少內(nèi)存占用,這樣就可以繼續(xù)增加批尺寸。
記住,你很可能需要再次更新學(xué)習(xí)率。如果將批尺寸增加一倍,最好將學(xué)習(xí)速度也提高一倍。
4. 累積梯度
假如已經(jīng)最大限度地使用了計(jì)算資源,而批尺寸仍然太低(假設(shè)為8),那我們則需為梯度下降模擬更大的批尺寸,以供精準(zhǔn)估計(jì)。
假設(shè)想讓批尺寸達(dá)到128。然后,在執(zhí)行單個(gè)優(yōu)化器步驟前,將執(zhí)行16次前向和后向傳播(批量大小為8)。
#clearlaststep
optimizer.zero_grad()
#16accumulatedgradientsteps
scaled_loss=0
foraccumulated_step_iinrange(16):
out=model.forward()
loss=some_loss(out,y)
loss.backward()
scaled_loss+=loss.item()
#updateweightsafter8steps.effectivebatch=8*16
optimizer.step()
#lossisnowscaledupbythenumberofaccumulatedbatches
actual_loss=scaled_loss/16properties
而在Lightning中,這些已經(jīng)自動(dòng)執(zhí)行了。只需設(shè)置標(biāo)記:
trainer=Trainer(accumulate_grad_batches=16)
trainer.fit(model)
5. 保留計(jì)算圖
撐爆內(nèi)存很簡(jiǎn)單,只要不釋放指向計(jì)算圖形的指針,比如……為記錄日志保存loss。
losses=[]
...
losses.append(loss)
print(f'currentloss:)
上述的問題在于,loss仍然有一個(gè)圖形副本。在這種情況中,可用.item()來釋放它。
#bad
losses.append(loss)
#good
losses.append(loss.item())
Lightning會(huì)特別注意,讓其無法保留圖形副本。示例:https://github.com/williamFalcon/pytorch-lightning/blob/master/pytorch_lightning/models/trainer.py#L812
6. 單GPU訓(xùn)練
一旦完成了前面的步驟,就可以進(jìn)入GPU訓(xùn)練了。GPU的訓(xùn)練將對(duì)許多GPU核心上的數(shù)學(xué)計(jì)算進(jìn)行并行處理。能加速多少取決于使用的GPU類型。個(gè)人使用的話,推薦使用2080Ti,公司使用的話可用V100。
剛開始你可能會(huì)覺得壓力很大,但其實(shí)只需做兩件事:1)將你的模型移動(dòng)到GPU上,2)在用其運(yùn)行數(shù)據(jù)時(shí),把數(shù)據(jù)導(dǎo)至GPU中。
#putmodelonGPU
model.cuda(0)
#putdataongpu(cudaonavariablereturnsacudacopy)
x=x.cuda(0)
#runsonGPUnow
model(x)
如果使用Lightning,則不需要對(duì)代碼做任何操作。只需設(shè)置標(biāo)記:
#asklightningtousegpu0fortraining
trainer=Trainer(gpus=[0])
trainer.fit(model)
在GPU進(jìn)行訓(xùn)練時(shí),要注意限制CPU和GPU之間的傳輸量。
#expensive
x=x.cuda(0)
#veryexpensive
x=x.cpu()
x=x.cuda(0)
例如,如果耗盡了內(nèi)存,不要為了省內(nèi)存,將數(shù)據(jù)移回CPU。嘗試用其他方式優(yōu)化代碼,或者在用這種方法之前先跨GPUs分配代碼。
此外還要注意進(jìn)行強(qiáng)制GPUs同步的操作。例如清除內(nèi)存緩存。
#reallybadidea.StopsalltheGPUsuntiltheyallcatchup
torch.cuda.empty_cache()
但是如果使用Lightning,那么只有在定義Lightning模塊時(shí)可能會(huì)出現(xiàn)這種問題。Lightning特別注意避免此類錯(cuò)誤。
7. 16位精度
16位精度可以有效地削減一半的內(nèi)存占用。大多數(shù)模型都是用32位精度數(shù)進(jìn)行訓(xùn)練的。然而最近的研究發(fā)現(xiàn),使用16位精度,模型也可以很好地工作。混合精度指的是,用16位訓(xùn)練一些特定的模型,而權(quán)值類的用32位訓(xùn)練。
要想在Pytorch中用16位精度,先從NVIDIA中安裝 apex 圖書館 并對(duì)你的模型進(jìn)行這些更改。
#enable16-bitonthemodelandtheoptimizer
model,optimizers=amp.initialize(model,optimizers,opt_level='O2')
#whendoing.backward,letampdoitsoitcanscaletheloss
withamp.scale_loss(loss,optimizer)asscaled_loss:
scaled_loss.backward()
amp包會(huì)處理大部分事情。如果梯度爆炸或趨于零,它甚至?xí)U(kuò)大loss。
在Lightning中, 使用16位很簡(jiǎn)單,不需對(duì)你的模型做任何修改,也不用完成上述操作。
trainer=Trainer(amp_level=’O2',use_amp=False)
trainer.fit(model)
8. 移至多GPU
現(xiàn)在,事情就變得有意思了。有3種(也許更多?)方式訓(xùn)練多GPU。
- 分批量訓(xùn)練
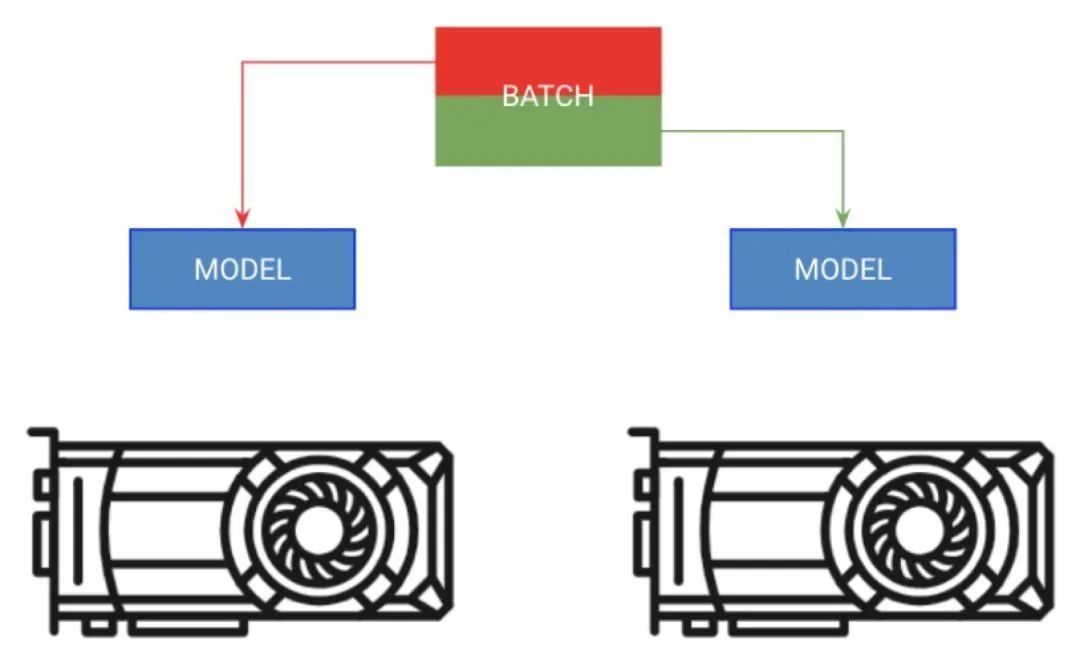
第一種方法叫做分批量訓(xùn)練。這一策略將模型復(fù)制到每個(gè)GPU上,而每個(gè)GPU會(huì)分到該批量的一部分。
#copymodeloneachGPUandgiveafourthofthebatchtoeach
model=DataParallel(model,devices=[0,1,2,3])
#outhas4outputs(oneforeachgpu)
out=model(x.cuda(0))
在Lightning中,可以直接指示訓(xùn)練器增加GPU數(shù)量,而無需完成上述任何操作。
#asklightningtouse4GPUsfortraining
trainer=Trainer(gpus=[0,1,2,3])
trainer.fit(model)
- 分模型訓(xùn)練
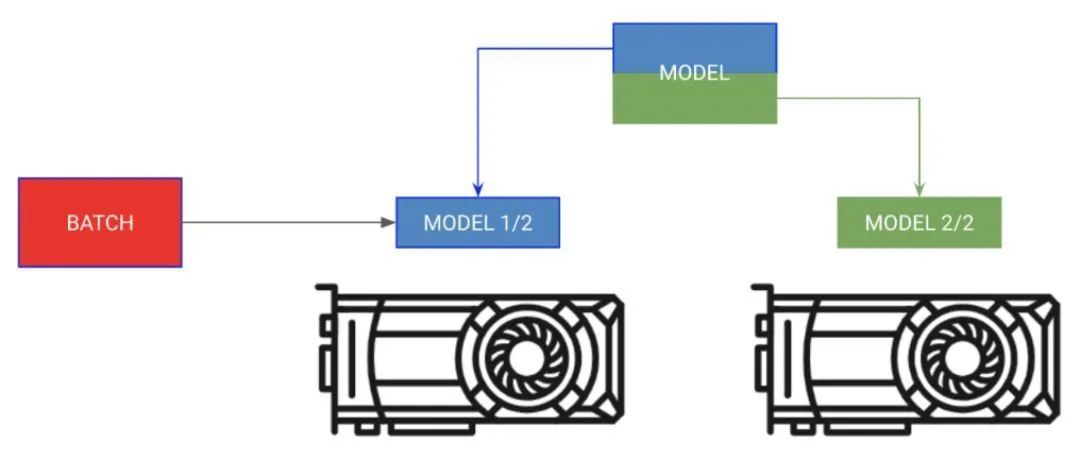
有時(shí)模型可能太大,內(nèi)存不足以支撐。比如,帶有編碼器和解碼器的Sequence to Sequence模型在生成輸出時(shí)可能會(huì)占用20gb的內(nèi)存。在這種情況下,我們希望把編碼器和解碼器放在單獨(dú)的GPU上。
#eachmodelissooobigwecan'tfitbothinmemory
encoder_rnn.cuda(0)
decoder_rnn.cuda(1)
#runinputthroughencoderonGPU0
out=encoder_rnn(x.cuda(0))
#runoutputthroughdecoderonthenextGPU
out=decoder_rnn(x.cuda(1))
#normallywewanttobringalloutputsbacktoGPU0
out=out.cuda(0)
對(duì)于這種類型的訓(xùn)練,無需將Lightning訓(xùn)練器分到任何GPU上。與之相反,只要把自己的模塊導(dǎo)入正確的GPU的Lightning模塊中:
classMyModule(LightningModule):
def__init__():
self.encoder=RNN(...)
self.decoder=RNN(...)
defforward(x):
#modelswon'tbemovedafterthefirstforwardbecause
#theyarealreadyonthecorrectGPUs
self.encoder.cuda(0)
self.decoder.cuda(1)
out=self.encoder(x)
out=self.decoder(out.cuda(1))
#don'tpassGPUstotrainer
model=MyModule()
trainer=Trainer()
trainer.fit(model)
- 混合兩種訓(xùn)練方法
在上面的例子中,編碼器和解碼器仍然可以從并行化每個(gè)操作中獲益。我們現(xiàn)在可以更具創(chuàng)造力了。
#changetheselines
self.encoder=RNN(...)
self.decoder=RNN(...)
#tothese
#noweachRNNisbasedonadifferentgpuset
self.encoder=DataParallel(self.encoder,devices=[0,1,2,3])
self.decoder=DataParallel(self.encoder,devices=[4,5,6,7])
#inforward...
out=self.encoder(x.cuda(0))
#noticeinputsonfirstgpuindevice
sout=self.decoder(out.cuda(4))#<---?the?4?here
使用多GPUs時(shí)需注意的事項(xiàng)
-
如果該設(shè)備上已存在model.cuda(),那么它不會(huì)完成任何操作。
-
始終輸入到設(shè)備列表中的第一個(gè)設(shè)備上。
-
跨設(shè)備傳輸數(shù)據(jù)非常昂貴,不到萬(wàn)不得已不要這樣做。
-
優(yōu)化器和梯度將存儲(chǔ)在GPU 0上。因此,GPU 0使用的內(nèi)存很可能比其他處理器大得多。
9. 多節(jié)點(diǎn)GPU訓(xùn)練
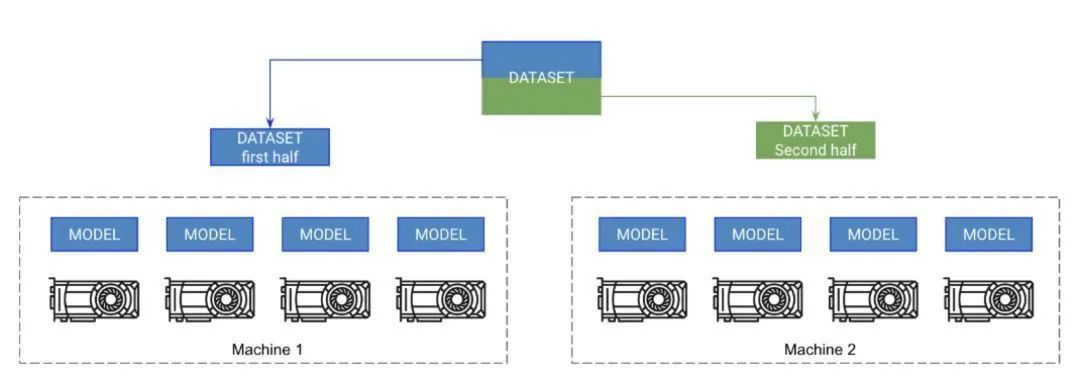
每臺(tái)機(jī)器上的各GPU都可獲取一份模型的副本。每臺(tái)機(jī)器分得一部分?jǐn)?shù)據(jù),并僅針對(duì)該部分?jǐn)?shù)據(jù)進(jìn)行訓(xùn)練。各機(jī)器彼此同步梯度。
做到了這一步,就可以在幾分鐘內(nèi)訓(xùn)練Imagenet數(shù)據(jù)集了! 這沒有想象中那么難,但需要更多有關(guān)計(jì)算集群的知識(shí)。這些指令假定你正在集群上使用SLURM。
Pytorch在各個(gè)GPU上跨節(jié)點(diǎn)復(fù)制模型并同步梯度,從而實(shí)現(xiàn)多節(jié)點(diǎn)訓(xùn)練。因此,每個(gè)模型都是在各GPU上獨(dú)立初始化的,本質(zhì)上是在數(shù)據(jù)的一個(gè)分區(qū)上獨(dú)立訓(xùn)練的,只是它們都接收來自所有模型的梯度更新。
高級(jí)階段:
-
在各GPU上初始化一個(gè)模型的副本(確保設(shè)置好種子,使每個(gè)模型初始化到相同的權(quán)值,否則操作會(huì)失效。)
-
將數(shù)據(jù)集分成子集。每個(gè)GPU只在自己的子集上訓(xùn)練。
-
On .backward() 所有副本都會(huì)接收各模型梯度的副本。只有此時(shí),模型之間才會(huì)相互通信。
Pytorch有一個(gè)很好的抽象概念,叫做分布式數(shù)據(jù)并行處理,它可以為你完成這一操作。要使用DDP(分布式數(shù)據(jù)并行處理),需要做4件事:
deftng_dataloader(,m):
d=MNIST()
#4:Adddistributedsampler
#samplersendsaportionoftngdatatoeachmachine
dist_sampler=DistributedSampler(dataset)
dataloader=DataLoader(d,shuffle=False,sampler=dist_sampler)
defmain_process_entrypoint(gpu_nb):
#2:setupconnectionsbetweenallgpusacrossallmachines
#allgpusconnecttoasingleGPU"root"
#thedefaultusesenv://
world=nb_gpus*nb_nodes
dist.init_process_group("nccl",rank=gpu_nb,world_size=world)
#3:wrapmodelinDPP
torch.cuda.set_device(gpu_nb)
model.cuda(gpu_nb)
model=DistributedDataParallel(model,device_ids=[gpu_nb])
#trainyourmodelnow...
if__name__=='__main__':
#1:spawnnumberofprocesses
#yourclusterwillcallmainforeachmachine
mp.spawn(main_process_entrypoint,nprocs=8)
Pytorch團(tuán)隊(duì)對(duì)此有一份詳細(xì)的實(shí)用教程:https://github.com/pytorch/examples/blob/master/imagenet/main.py?source=post_page
然而,在Lightning中,這是一個(gè)自帶功能。只需設(shè)定節(jié)點(diǎn)數(shù)標(biāo)志,其余的交給Lightning處理就好。
#trainon1024gpusacross128nodes
trainer=Trainer(nb_gpu_nodes=128,gpus=[0,1,2,3,4,5,6,7])
Lightning還附帶了一個(gè)SlurmCluster管理器,可助你簡(jiǎn)單地提交SLURM任務(wù)的正確細(xì)節(jié)。示例:https://github.com/williamFalcon/pytorch-lightning/blob/master/examples/new_project_templates/multi_node_cluster_template.py#L103-L134
10. 福利!更快的多GPU單節(jié)點(diǎn)訓(xùn)練
事實(shí)證明,分布式數(shù)據(jù)并行處理要比數(shù)據(jù)并行快得多,因?yàn)槠湮ㄒ坏耐ㄐ攀翘荻韧健R虼耍詈糜梅植际綌?shù)據(jù)并行處理替換數(shù)據(jù)并行,即使只是在做單機(jī)訓(xùn)練。
在Lightning中,通過將distributed_backend設(shè)置為ddp(分布式數(shù)據(jù)并行處理)并設(shè)置GPU的數(shù)量,這可以很容易實(shí)現(xiàn)。
#trainon4gpusonthesamemachineMUCHfasterthanDataParallel
trainer=Trainer(distributed_backend='ddp',gpus=[0,1,2,3])
有關(guān)模型加速的思考和技巧
如何通過尋找瓶頸來思考問題?可以把模型分成幾個(gè)部分:
首先,確保數(shù)據(jù)加載中沒有瓶頸。為此,可以使用上述的現(xiàn)有數(shù)據(jù)加載方案,但是如果沒有適合你的方案,你可以把離線處理及超高速緩存作為高性能數(shù)據(jù)儲(chǔ)存,就像h5py一樣。
接下來看看在訓(xùn)練過程中該怎么做。確保快速轉(zhuǎn)發(fā),避免多余的計(jì)算,并將CPU和GPU之間的數(shù)據(jù)傳輸最小化。最后,避免降低GPU的速度(在本指南中有介紹)。
接下來,最大化批尺寸,通常來說,GPU的內(nèi)存大小會(huì)限制批量大小。自此看來,這其實(shí)就是跨GPU分布,但要最小化延遲,有效使用大批次(例如在數(shù)據(jù)集中,可能會(huì)在多個(gè)GPUs上獲得8000+的有效批量大小)。
但是需要小心處理大批次。根據(jù)具體問題查閱文獻(xiàn),學(xué)習(xí)一下別人是如何處理的!
原文鏈接:https://towardsdatascience.com/9-tips-for-training-lightning-fast-neural-networks-in-pytorch-8e63a502f565
-
cpu
+關(guān)注
關(guān)注
68文章
11061瀏覽量
216445 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7250瀏覽量
91502 -
gpu
+關(guān)注
關(guān)注
28文章
4925瀏覽量
130892 -
pytorch
+關(guān)注
關(guān)注
2文章
809瀏覽量
13854
原文標(biāo)題:用Pytorch訓(xùn)練快速神經(jīng)網(wǎng)絡(luò)的9個(gè)技巧
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論